
前回の記事で、衛星データを使った植生指数の季節変化を捉えるところまでを紹介しました。衛星データは多くの情報を内包していますが、ドローンによる撮影やGISデータを合わせることで、より詳細な解析に利用されます。
今回は、GISデータの一つであるシェープファイルデータを成形し、pythonのGeoPandasというライブラリで取り扱うまでを紹介します。
macOS Monterey(12.6), python3.10.7
Windows 11(21H2), python3.10.7, PowerShell(5.1)

Pythonを使った衛星データ解析の初心者向け技術書を販売中!
¥2,500 → ¥800 今なら約70%OFF!!
Google Earth Engineを使えば簡単に
自宅にいながら地球環境の変動を観察できます
シェープファイルとは?
シェープファイルとは、図形情報と属性情報を持ったベクターデータの一つでGISデータのファイル形式の一つです。シェープファイルを扱うことで、どこに、どれくらいの広さで、何があるかがわかります。日本では産総研が地質情報を、環境省が植生情報を配布しています。ほかにも色々な情報が配布されています。
シェープファイルの構成
シェープファイルはアメリカのESRI社が80年代に提唱した形式で、以下のような複数のファイルから構成されます。
- .shp:図形情報が格納
- .dbf:属性情報が格納
- .shx:shpとdbfの対応関係が格納
他にもオプションとしていくつかのファイルが存在しますが、この3つのファイルは必須となっています。
シェープファイルはこのように拡張子が異なる複数のファイルからなるため、管理が煩雑になる問題があります。さらに、それぞれのファイルは2 GBまでの情報しか格納できないため、ビッグデータ解析が主流になりつつあるGIS分野ではGeoJSONに置き換わりつつあります。
シェープファイルの細かい仕様や特徴などはESRI社が下記サイトで案内しているのでご参照ください。
https://www.esrij.com/getting-started/learn-more/shapefile/
シェープファイルを地図上にプロットするpythonの実装
それでは、シェープファイルの地図上にプロットする実装をpythonでコーディングしてみます。以下に実装例を示します。
利用するデータ
今回は環境省自然環境局の生物多様性センターが公開している植生調査のデータを利用します。下記のリンク先で都道府県ごとに調査されたデータが配布されているので、東京都のデータをダウンロードしてみます。
http://gis.biodic.go.jp/webgis/sc-025.html?kind=vg67
ダウンロードしたzipファイルは以下のようにshpxxxxxx.zipといった複数のzipファイルが格納されておりその配下にshpファイルが格納されています。zipファイルのままでは扱えないため、適当なものを解凍しておきます。
vg67_13.zip
|_ shp364123.zip
|_ p364123.shp
|_ p364123.dbf
|_ p364123.shx
|_ shp374102.zipソースコード
下記のコードをGIS_test.pyという名前でDesktop/labcode/ディレクトリに保存します。
import json
import fiona
import folium
import geopandas as gpd
import pandas as pd
from shapely.geometry import shape
# shpファイルの読み込み
path_shp = './shp533940/p533940.shp'
collection = list(fiona.open(path_shp,'r',encoding = 'shift-jis'))
# shpファイルをデータフレームに変換
df1 = pd.DataFrame(collection)
#geometryチェック用関数
def isvalid(geom):
try:
shape(geom)
return 1
except:
return 0
#geometryのチェック
df1['isvalid'] = df1['geometry'].apply(lambda x: isvalid(x))
df1 = df1[df1['isvalid'] == 1]
collection = json.loads(df1.to_json(orient='records'))
# geodataframeに変換
gdf = gpd.GeoDataFrame.from_features(collection).rename(columns=str.lower)
gdf.to_csv('vegetation.csv')
# GeoJsonの生成
gdf_json = gdf.to_json()
# マップの描画設定
lat, lon = 35.71,139.03
my_map = folium.Map(location=[lat, lon], zoom_start=10, control_scale=True)
folium.GeoJson(gdf_json, name='vegetation').add_to(my_map)
# アカマツ植林を抽出
gdf_tree = gdf.loc[gdf['hanrei_n'] == 'アカマツ植林']
gdf_tree = gdf_tree.reset_index()
gdf_tree_json = gdf_tree.to_json()
folium.GeoJson(gdf_tree_json, name='vg_tree').add_to(my_map)
# 複数のマップを重ね合わせる
my_map.add_child(folium.LayerControl(collapsed = False).add_to(my_map))
# マップの保存
my_map.save('GIS.html')プログラムを実行する
Macではターミナル、WindowsではPowerShellを開き
$ cd Desktop/labcode/と入力し、ディレクトリを移動します。あとは以下のコマンドを実行するだけです。( $マークは無視してください)
$ python GIS_test.py実行結果
/Desktop/labcode/ にvegetation.csvとGIS.htmlというファイルができていれば成功です!
GIS.htmlを開くと以下のようなマップが表示されます。今回は東京の奥多摩から山梨県の県境あたりの植生が表示されています。
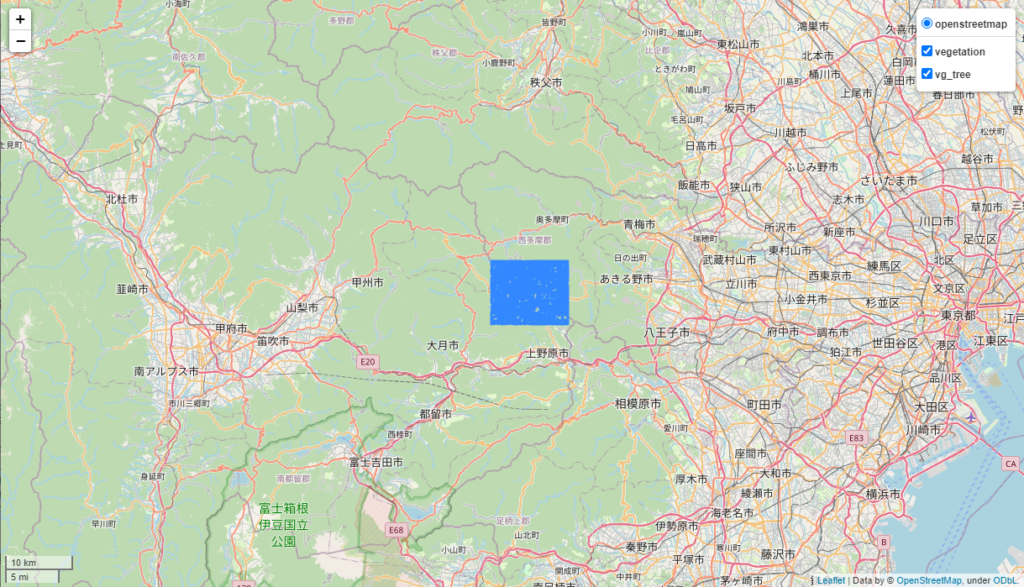
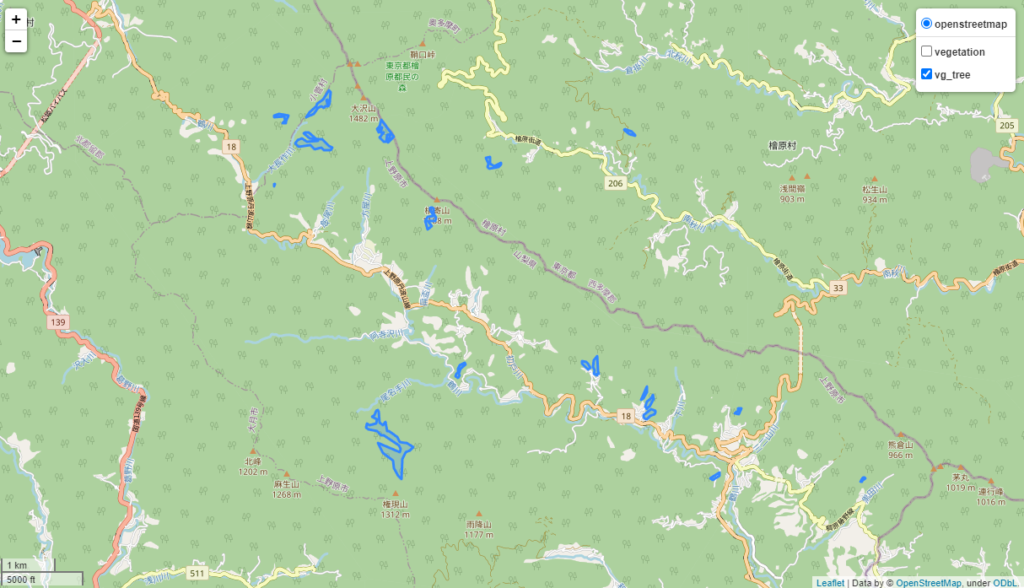
右上のレイヤーでvg_treeを選択し、マップを拡大すると以下のような表示になります。アカマツ植林でフィルターをかけているためこの地点にはアカマツの林が存在することがわかります。
コードの解説
上に書いたソースコードで重要なところを解説をしていきます。
import json
import fiona
import folium
import geopandas as gpd
import pandas as pd
from shapely.geometry import shapefiona、folium、geopandas、pandas、shapelyのライブラリを使用します。
fiona:shpファイルなどの地理情報を扱うデータの読み書きが行うライブラリ
geopandas:地理情報を扱ったデータをpandasのように扱うライブラリ
shaply:地理空間データの処理を行うライブラリ
# shpファイルの読み込み
path_shp = './shp533940/p533940.shp'
collection = list(fiona.open(path_shp,'r',encoding = 'shift-jis'))
# shpファイルをデータフレームに変換
df1 = pd.DataFrame(collection)fiona.openでshpファイルを読み込みます。日本の機関が提供しているシェープファイルは日本語が含まれていることが多いため、encoding = 'shift-jis'で文字コードを指定します。
#geometryチェック用関数
def isvalid(geom):
try:
shape(geom)
return 1
except:
return 0shpファイルのgeometryが有効な形状をしているかをチェックする関数です。有効な場合は1を返します。
geometryはPoint(点)、Polyline(線)、Polygon(面)などの型があります。これら以外の型が含まれている場合、データ処理を行うとエラーが発生します。そのため、この関数であらかじめ不要なデータを除外します。
#geometryのチェック
df1['isvalid'] = df1['geometry'].apply(lambda x: isvalid(x))
df1 = df1[df1['isvalid'] == 1]
# df1の行ごとにjson出力
collection = json.loads(df1.to_json(orient='records'))
# geodataframeに変換
gdf = gpd.GeoDataFrame.from_features(collection).rename(columns=str.lower)
gdf.to_csv('vegetation.csv') # データフレームをcsvとして保存2行目でisvalid関数の戻り値をデータフレームに新しく列として保存します。3行目でisvalidの戻り値が1のみデータを抽出し新たにデータフレームとして成形します。
6行目でdf1の行ごとにjson形式で出力します。
9行目で出力したgeopandasのデータフレームに変換します。rename(columns=str.lower)でカラム名を小文字に整えます。複数のshpファイルを扱う場合、カラム名が多岐にわたる場合があるため、処理をしやすくするために行います。今回は特に在っても無くても構いません。
# アカマツ植林を抽出
gdf_tree = gdf.loc[gdf['hanrei_n'] == 'アカマツ植林']
gdf_tree = gdf_tree.reset_index()2行目ではアカマツ植林の植生に持つデータを抽出しています。生物多様性センターのシェープファイルはhanrei_nに植生情報が属性として格納されています。今回はアカマツ植林を抽出しましたが、この箇所を変更することでほかにも色々な植生情報を抽出できます。
3行目ではreset_index()でindexを振り直しています。2行目の時点では抽出前のindexをもつため、歯抜けのようなindexを持つデータフレームになっています。今回は必須ではありませんが、降り直すことでデータ解析にまわすのが容易になります。
最後に
シェープファイルの利用について紹介しました。シェープファイルは色々な機関が配布しており、地理情報の解析によく用いられます。また、geometryの情報を持つため、衛星データと合わせることで、より解像度の高い解析が行えます。
次回は、シェープファイルのgeometryを衛星データの収集に利用できる形に変換する方法を解説したいと思います。
Pythonを使った衛星データ解析の初心者向け技術書を販売中!
¥2,500 → ¥800 今なら約70%OFF!!
Google Earth Engineを使えば簡単に
自宅にいながら地球環境の変動を観察できます

