
音声データの解析、加工をPythonでやってみたいと思ったことはありませんか?
前回の記事ではpydubを使って,音声データを時系列信号として読み込む方法を紹介しました。この記事では,入力音声データを加工しpydubを使って再び音声データとして出力する方法を紹介します。
また,本記事で紹介するフィルタリング操作 (ローパスフィルタ,ハイパスフィルタ) は音声データに限らず,様々な時系列データに対して適用することができます。
macOS Big Sur, python3.7.9, pydub0.25.1

Pythonで音声データを加工し,出力する方法
音声データの加工(ローパスフィルタとハイパスフィルタ)
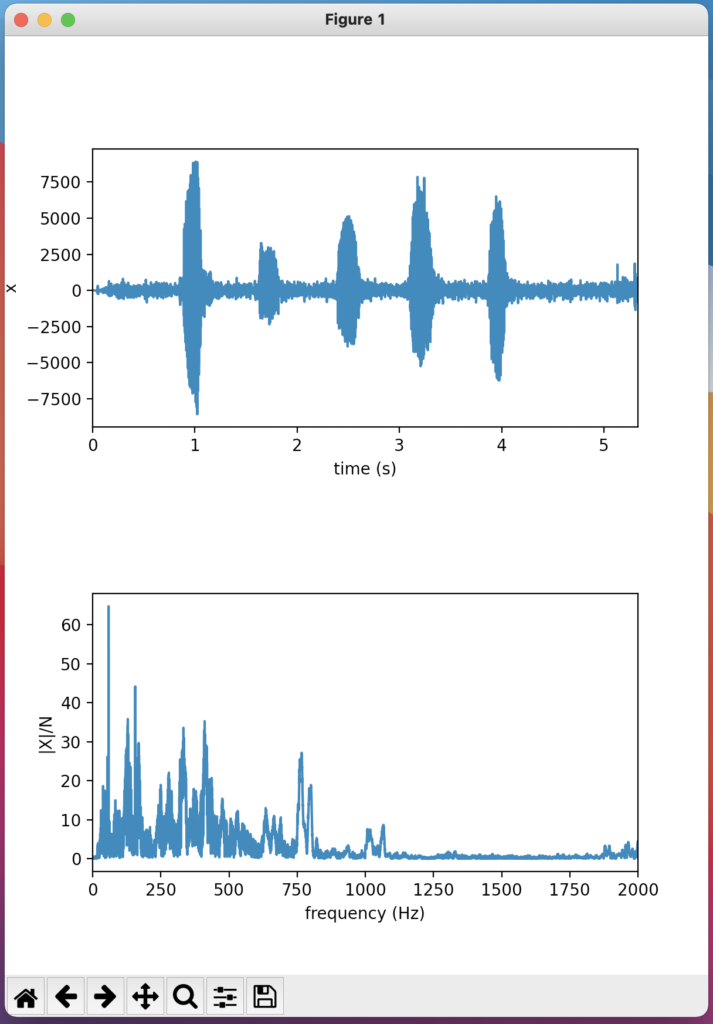
音声データは,一般に様々な周波数の振動から構成されています。下の図は私が「あいうえお」とゆっくりマイクに向かって喋った音声の波形とその振幅スペクトルです(この図の作り方は前回の記事で紹介しています)。振幅スペクトルを見るといくつかのピークが見られます。
音声データに限らず,時系列データを取り扱う場面では,ある領域の周波数成分のみを取り出してデータを加工したいことがあります。これを実現するのがフィルタリング操作です。
低い周波数成分のみを取り出すフィルタをローパスフィルタ (low-pass filter: LPF),高い周波数成分のみを取り出すフィルタをハイパスフィルタ(high-pass filter: HPF)といいます。
また,低いとか高いとかではなく,ある領域の周波数成分のみを通過させるフィルタをバンドパスフィルタ (band-pass filter: BPF) といいます。
以上のフィルタリング操作(LPFとHPF)をPythonで実装し,読み込んだ音声データに適用して加工し,音声データとして出力してみます。これを行うには,下記のようなコードを書きます。書いたら,edit-sounds.pyという名前で適当なディレクトリに保存します (ここでは,~/Desktop/LabCode/python/edit-sounds を例として使用します)。
音声データの読み込みと書き出しには pydub を使用します。インストール方法については,前回の記事で説明しています。
mport matplotlib.pyplot as plt
import numpy as np
from pydub import AudioSegment
# ボイスメモで収録したm4aファイルを読み込む
sounds = AudioSegment.from_file('aiueo.m4a', 'm4a')
# 基本情報の表示
print(f'channel: {sounds.channels}')
print(f'frame rate: {sounds.frame_rate}')
print(f'duration: {sounds.duration_seconds} s')
print(f'sample width: {sounds.sample_width}')
# チャンネルが2 (ステレオ) の場合,交互にデータが入っているので,二つおきに読み出す。
# ただし,今回の場合はモノラルのはず。つまり,sounds.channels = 1
sig = np.array(sounds.get_array_of_samples())[::sounds.channels]
dt = 1.0/sounds.frame_rate # サンプリング時間
# 時間アレイを作る
tms = 0.0 # サンプル開始時間を0にセット
tme = sounds.duration_seconds # サンプル終了時刻
tm = np.linspace(tms, tme, len(sig), endpoint=False) # 時間numpy配列を作成
# DFT
N = len(sig)
X = np.fft.fft(sig)
f = np.fft.fftfreq(N, dt) # Xのindexに対応する周波数のnumpy配列を取得
# ローパスフィルタ
f_cutoff_LPF = 5.0e2 # カットオフ周波数
X_LPFed = X.copy()
X_LPFed[(f > f_cutoff_LPF) | (f < -f_cutoff_LPF)] = 0.0 # カットオフ周波数より大きい周波数成分を0に
sig_LPFed = np.real(np.fft.ifft(X_LPFed))
# 音声データの書き出し
sounds_LPFed = AudioSegment(sig_LPFed.astype("int16").tobytes(),
sample_width=sounds.sample_width,
frame_rate=sounds.frame_rate, channels=1)
sounds_LPFed.export("aiueo_LPFed.mp3", format="mp3")
# ハイパスフィルタ
f_cutoff_HPF = 10.0e2 # カットオフ周波数
X_HPFed = X.copy()
X_HPFed[((f > 0) & (f < f_cutoff_HPF)) | ((f < 0) & (f > -f_cutoff_HPF))] = 0.0 #カットオフ周波数より小さい周波数成分を0に
sig_HPFed = np.real(np.fft.ifft(X_HPFed))
# 音声データの書き出し
sounds_HPFed = AudioSegment(sig_HPFed.astype("int16").tobytes(),
sample_width=sounds.sample_width,
frame_rate=sounds.frame_rate, channels=1)
sounds_HPFed.export("aiueo_HPFed.mp3", format="mp3")
# データをプロット (なくても良い)
fig, (ax01, ax02) = plt.subplots(nrows=2, figsize=(6, 8))
plt.subplots_adjust(wspace=0.0, hspace=0.6)
ax01.set_xlim(tms, tme)
ax01.set_xlabel('time (s)')
ax01.set_ylabel('x')
ax01.plot(tm, sig, color='black') # 入力信号
ax01.plot(tm, sig_LPFed, color='blue') # LPF後の波形
ax01.plot(tm, sig_HPFed, color='orange') # LPF後の波形
ax02.set_xlim(0, 2000)
ax02.set_xlabel('frequency (Hz)')
ax02.set_ylabel('|X|/N')
ax02.plot(f[0:N//2], np.abs(X[0:N//2])/N, color='black') # 振幅スペクトル
ax02.plot(f[0:N//2], np.abs(X_LPFed[0:N//2])/N, color='blue') # 振幅スペクトル
ax02.plot(f[0:N//2], np.abs(X_HPFed[0:N//2])/N, color='orange') # 振幅スペクトル
plt.show()音声データとしては何でも使用できますが,ここでは,自分の声を加工してみます。ボイスメモで録音し,適当な名前(ここでは「aiueo.m4a」)をつけて,先程コードを保存したディレクトリ(~/Desktop/LabCode/python/edit-sounds )に保存します。
プログラムを実行する
ターミナルを開き,
$ cd ~/Desktop/LabCode/python/edit-soundsと入力し,ディレクトリを移動します。あとは以下のコマンドで edit-sounds.pyを実行するだけです。( $マークは無視してください)。
$ python3 edit-sounds.py実行結果
先程録音した音声ファイルの名前を好きな名前(ここでは「aiueo.m4a」)に変更し,pythonスクリプトを保存するディレクトリ(例えば,Desktop/LabCode/python/read-sounds)に配置します。
import matplotlib.pyplot as plt
import numpy as np
from pydub import AudioSegment
# ボイスメモで収録したm4aファイルを読み込む
sounds = AudioSegment.from_file('aiueo.m4a', 'm4a')
# 基本情報の表示
print(f'channel: {sounds.channels}')
print(f'frame rate: {sounds.frame_rate}')
print(f'duration: {sounds.duration_seconds} s')
# チャンネルが2 (ステレオ) の場合,交互にデータが入っているので,二つおきに読み出す。
# ただし,今回の場合はモノラルのはず。つまり,sounds.channels = 1
sig = np.array(sounds.get_array_of_samples())[::sounds.channels]
dt = 1.0/sounds.frame_rate # サンプリング時間
# 時間アレイを作る
tms = 0.0 # サンプル開始時間を0にセット
tme = sounds.duration_seconds # サンプル終了時刻
tm = np.linspace(tms, tme, len(sig), endpoint=False) # 時間ndarrayを作成
# DFT
N = len(sig)
X = np.fft.fft(sig)
f = np.fft.fftfreq(N, dt) # Xのindexに対応する周波数のndarrayを取得
# データをプロット
fig, (ax01, ax02) = plt.subplots(nrows=2, figsize=(6, 8))
plt.subplots_adjust(wspace=0.0, hspace=0.6)
ax01.set_xlim(tms, tme)
ax01.set_xlabel('time (s)')
ax01.set_ylabel('x')
ax01.plot(tm, sig) # 入力信号
ax02.set_xlim(0, 2000)
ax02.set_xlabel('frequency (Hz)')
ax02.set_ylabel('|X|/N')
ax02.plot(f[0:N//2], np.abs(X[0:N//2])/N) # 振幅スペクトル
plt.show()プログラムを実行する
ターミナルを開き,
$ cd Desktop/LabCode/python/read-soundsと入力し,ディレクトリを移動します。あとは以下のコマンドでpydub-demo.pyを実行するだけです。( $マークは無視してください)。
$ python3 pydub-demo.py実行結果
以下のようなウィンドウが立ち上がり,~/Desktop/LabCode/python/edit-sounds にaiueo_LPFed.mp3 と aiueo_HPFed.mp3 ができていれば成功です。
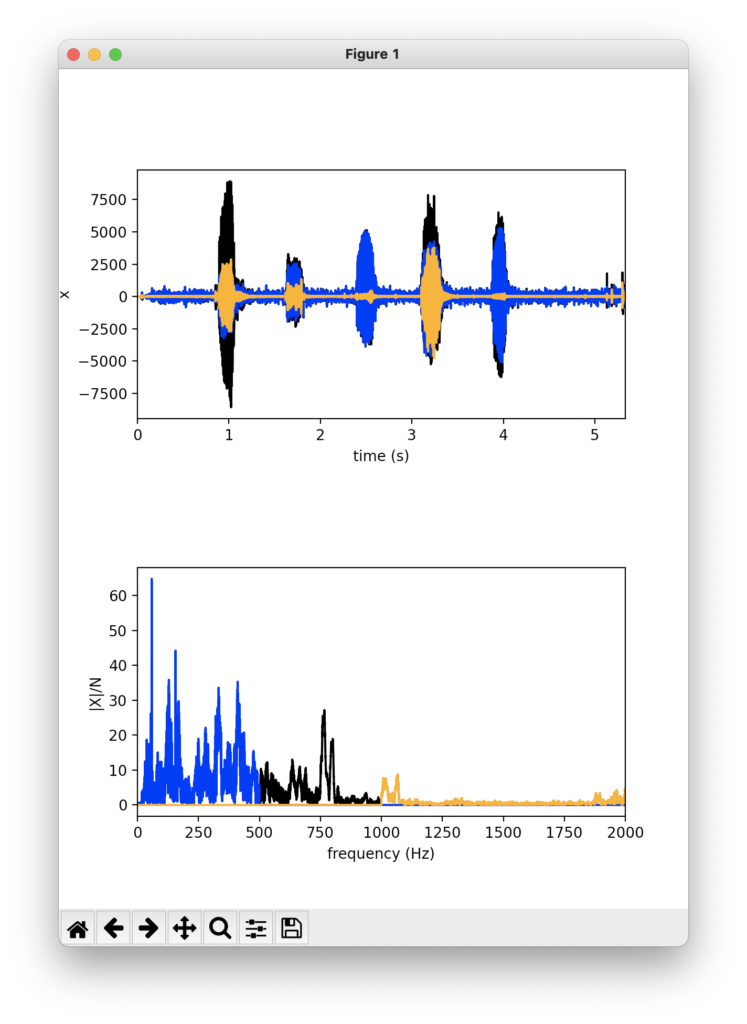
上段は横軸時間の音声波形,下段は振幅スペクトルです。黒が加工前,青がLPFをかけたもの,オレンジがHPFをかけたものです。
上のコードでは,カットオフ周波数500 HzのLPFとしましたが,見事に500Hzより大きい成分の振幅が0となっていることがわかります。HPFも同様に,1000 Hzより小さな成分は0となっています。
フィルタリングの効果は上段の波形を拡大しても理解することができます(虫眼鏡アイコンをクリックして範囲を選択すると拡大することができます)。
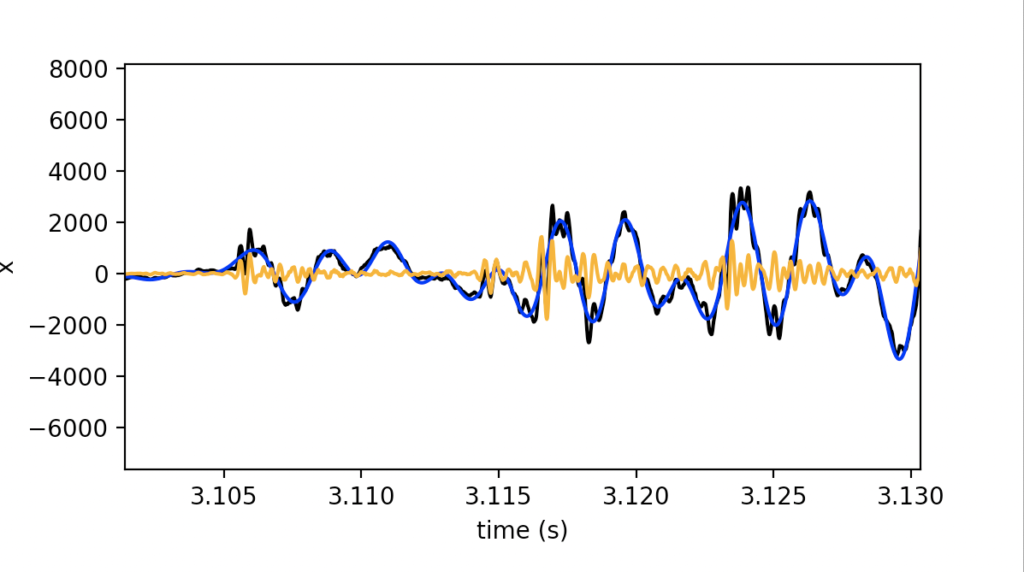
上の図は音声波形の3.12秒付近を拡大したものです。
黒色の生波形に対して,青のLPFされた波形はゆっくりとした成分のみとなっており,オレンジの波形は黒色の生波形に含まれる速く振動する成分から構成されていることがわかります。
生成された音声を聞いて,どのような声になっているか確認してみましょう。aiueo_LPFed.mp3はくぐもった低い声,aiueo_HPFed.mp3 は高い声になっていることが確認できると思います。
コードの解説
上で書いたコードの解説をします。
import matplotlib.pyplot as plt
import numpy as np
from pydub import AudioSegment必要なモジュールをインポートします。
# ボイスメモで収録したm4aファイルを読み込む
sounds = AudioSegment.from_file('aiueo.m4a', 'm4a')
# 基本情報の表示
print(f'channel: {sounds.channels}')
print(f'frame rate: {sounds.frame_rate}')
print(f'duration: {sounds.duration_seconds} s')
print(f'sample width: {sounds.sample_width}')
# チャンネルが2 (ステレオ) の場合,交互にデータが入っているので,二つおきに読み出す。
# ただし,今回の場合はモノラルのはず。つまり,sounds.channels = 1
sig = np.array(sounds.get_array_of_samples())[::sounds.channels]
dt = 1.0/sounds.frame_rate # サンプリング時間
# 時間アレイを作る
tms = 0.0 # サンプル開始時間を0にセット
tme = sounds.duration_seconds # サンプル終了時刻
tm = np.linspace(tms, tme, len(sig), endpoint=False) # 時間numpy配列を作成ボイスメモで録音したm4aファイルを読み込み,振幅をsigというnumpy配列に代入します。また,tmという時間のnumpy配列を作ります。
# DFT
N = len(sig)
X = np.fft.fft(sig)
f = np.fft.fftfreq(N, dt) # Xのindexに対応する周波数のnumpy配列を取得DFTを実行します。結果をXというnumpy配列に,Xのインデックスに対応する周波数のnumpy配列をfとします。
# ローパスフィルタ
f_cutoff_LPF = 5.0e2 # カットオフ周波数
X_LPFed = X.copy()
X_LPFed[(f > f_cutoff_LPF) | (f < -f_cutoff_LPF)] = 0.0 # カットオフ周波数より大きい周波数成分を0に
sig_LPFed = np.real(np.fft.ifft(X_LPFed))ローパスフィルタをかけます。f_cutoff_LPFはローパスフィルタのカットオフ周波数と呼ばれ,それよりも大きな周波数は通しません。つまり,それ以上の周波数成分を0にするという操作を行います。ここでは,f_cutoff_LPF = 5.0e2 とし,500 Hzのローパスフィルタとしました。
まず,X_LPFed = X.copy() によって,元信号のDFTの結果をコピーします。(.copy()でコピーを作成しなければ,このあとの操作でXも変化してしまうのでご注意ください。)その後,カットオフ周波数以上の周波数成分を0にします。最後にこれを逆DFTによって時間領域に戻し,実部をsig_LPFedに代入します。
# 音声データの書き出し
sounds_LPFed = AudioSegment(sig_LPFed.astype("int16").tobytes(),
sample_width=sounds.sample_width,
frame_rate=sounds.frame_rate, channels=1)
sounds_LPFed.export("aiueo_LPFed.mp3", format="mp3")音声データを書き出します。まず,AudioSegmentのオブジェクトにする必要があります。データをint16に変換し,バイト列に変換したものを第一引数とし,sample_widthやframe_rate,channelsを指定します。ここでは,入力ファイルと同じものとします。
# ハイパスフィルタ
f_cutoff_HPF = 10.0e2 # カットオフ周波数
X_HPFed = X.copy()
X_HPFed[((f > 0) & (f < f_cutoff_HPF)) | ((f < 0) & (f > -f_cutoff_HPF))] = 0.0 #カットオフ周波数より小さい周波数成分を0に
sig_HPFed = np.real(np.fft.ifft(X_HPFed))
# 音声データの書き出し
sounds_HPFed = AudioSegment(sig_HPFed.astype("int16").tobytes(),
sample_width=sounds.sample_width,
frame_rate=sounds.frame_rate, channels=1)
sounds_HPFed.export("aiueo_HPFed.mp3", format="mp3")ローパスフィルタと同様に,ハイパスフィルタをかけます。f_cutoff_HPF で指定した周波数よりも小さな成分を0にします。そうして得られた信号を,逆DFTにより時間領域に戻して,音声データとして書き出します。
# データをプロット (なくても良い)
fig, (ax01, ax02) = plt.subplots(nrows=2, figsize=(6, 8))
plt.subplots_adjust(wspace=0.0, hspace=0.6)
ax01.set_xlim(tms, tme)
ax01.set_xlabel('time (s)')
ax01.set_ylabel('x')
ax01.plot(tm, sig, color='black') # 入力信号
ax01.plot(tm, sig_LPFed, color='blue') # LPF後の波形
ax01.plot(tm, sig_HPFed, color='orange') # LPF後の波形
ax02.set_xlim(0, 2000)
ax02.set_xlabel('frequency (Hz)')
ax02.set_ylabel('|X|/N')
ax02.plot(f[0:N//2], np.abs(X[0:N//2])/N, color='black') # 振幅スペクトル
ax02.plot(f[0:N//2], np.abs(X_LPFed[0:N//2])/N, color='blue') # 振幅スペクトル
ax02.plot(f[0:N//2], np.abs(X_HPFed[0:N//2])/N, color='orange') # 振幅スペクトル
plt.show()最後にデータをプロットして,思った通りの操作ができているか確認します(この部分はこの記事のテーマである「音声データの加工と書き出し」において本質的な部分ではないため,確認不要な場合はなくても構いません)。
最後に
今回は,pydubを使用して音声データを読み込み,加工して再び音声データとして書き出す方法について紹介しました。
最初にも述べたとおり,記事で取り扱ったローパスフィルタやハイパスフィルタは時系列データ解析において多用される操作です。音声データに限らず,手持ちのデータでゆっくりと変化する成分と速く変化する成分を分離したいときなどに使用してみてください!

