
以前の記事で、シェープファイルを使った衛星データの収集方法などを紹介してきました。この方法ではシェープファイルをCSVファイルに置き換えていましたが、大量のデータを扱っていく場合だとCSVファイルでは処理が重くなり扱いづらいことがありました。
今回は入手したシェープファイルをBigQueryというサービス上に格納する方法を紹介します。BigQueryに格納することで、必要な地理情報の抜き出しが容易になり、衛星データやGIS解析への利用が容易になります。
macOS Ventura(13.3), python3.10.11

Pythonを使った衛星データ解析の初心者向け技術書を販売中!
¥2,500 → ¥800 今なら約70%OFF!!
Google Earth Engineを使えば簡単に
自宅にいながら地球環境の変動を観察できます
BigQuery とは?
BigQueryは、Google Cloud Platform (GCP) の一部として提供されている、フルマネージド型のデータウェアハウスサービスです。BigQueryは、大量のデータを効率的に分析するために設計されており、ペタバイト単位のデータを迅速かつ簡単にクエリすることができます。
BigQueryの主な特徴は以下のとおりです。
- スケーラビリティ: BigQueryは、データ量やクエリの複雑さに応じて自動的にスケーリングします。このため、追加のリソースやインフラストラクチャの管理が不要です。
- 高速性: Googleのインフラストラクチャと技術を利用して、大量のデータに対してリアルタイムに近いレスポンスでクエリを実行できます。
- セキュリティ: BigQueryは、データの暗号化やアクセス制御など、Googleの厳格なセキュリティ基準を満たしています。また、ユーザーは自分のデータセキュリティ要件に応じてカスタマイズすることもできます。
- 統合: BigQueryは、Google Cloud Platformの他のサービスや、外部のBIツール、データソースとの統合が容易です。これにより、データ分析のワークフローをシームレスに実行できます。
- SQLサポート: BigQueryは、標準SQLをサポートしているため、データ分析者や開発者がすでに習得しているSQLを利用してデータをクエリできます。
それでは実際にシェープファイルをBigQueryに格納する方法を紹介していきます。
実装方法
データセットを作成する(すでに使用するBigQueryがある場合は不要)
まず、GCPのコンソールにアクセスし利用するプロジェクトを選択もしくは作成します。
次に、左上のメニューアイコンをクリックしてナビゲーションメニューを開き、BigQueryを選択します。
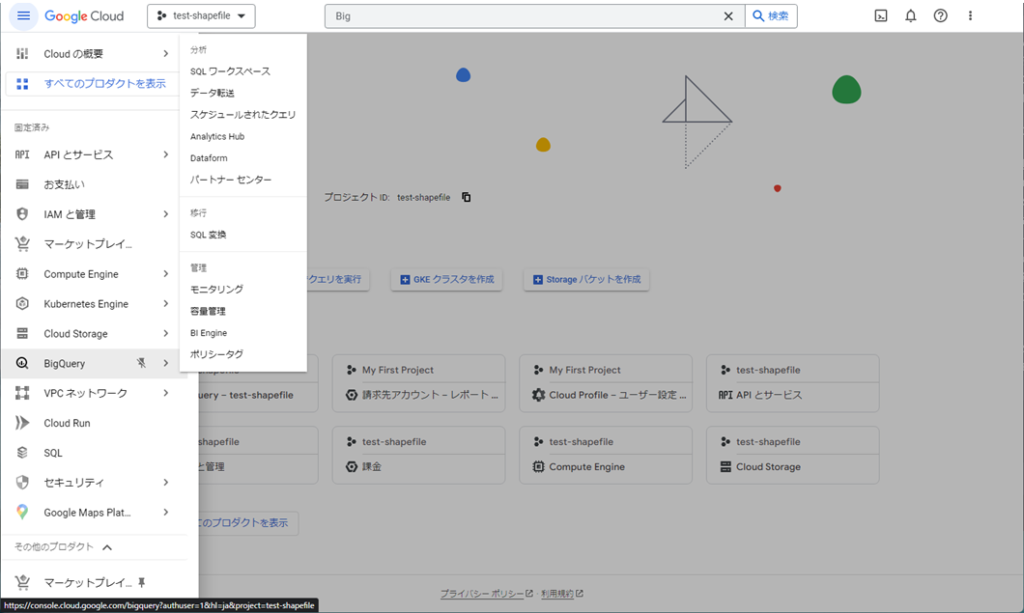
BigQueryのコンソールに移動したら、画面中央付近に表示されているプロジェクト名の赤枠の部分をクリックし、「データセットを作成」をクリックします。
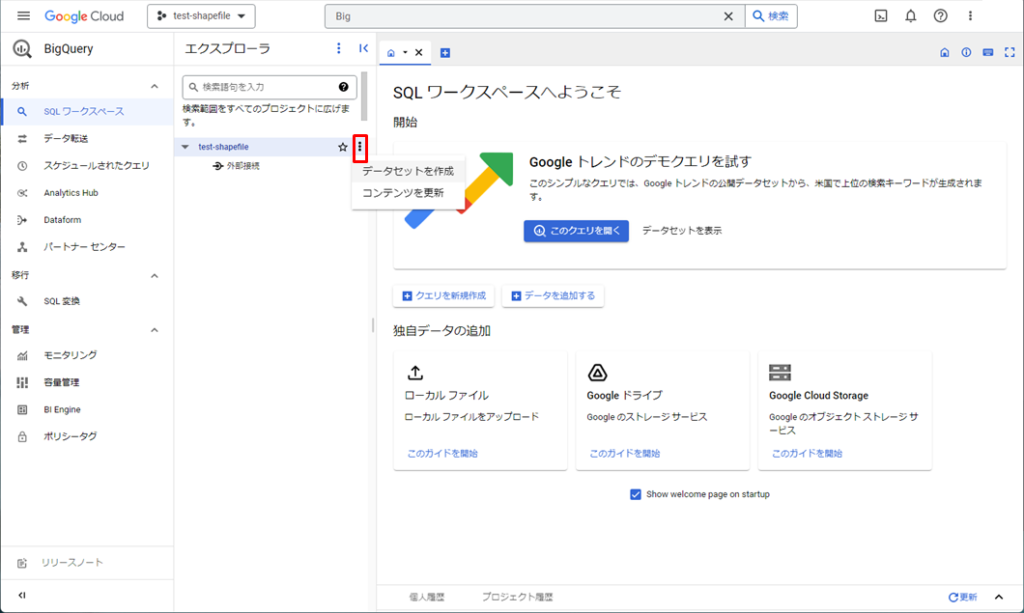
データセットの作成ウィンドウが表示されるので、データセットIDを入力し、必要に応じて他のオプションを設定します。
今回はデータセットID:shapefile_dataset、ロケーションタイプ:東京リージョンのデータセットを作成しました。
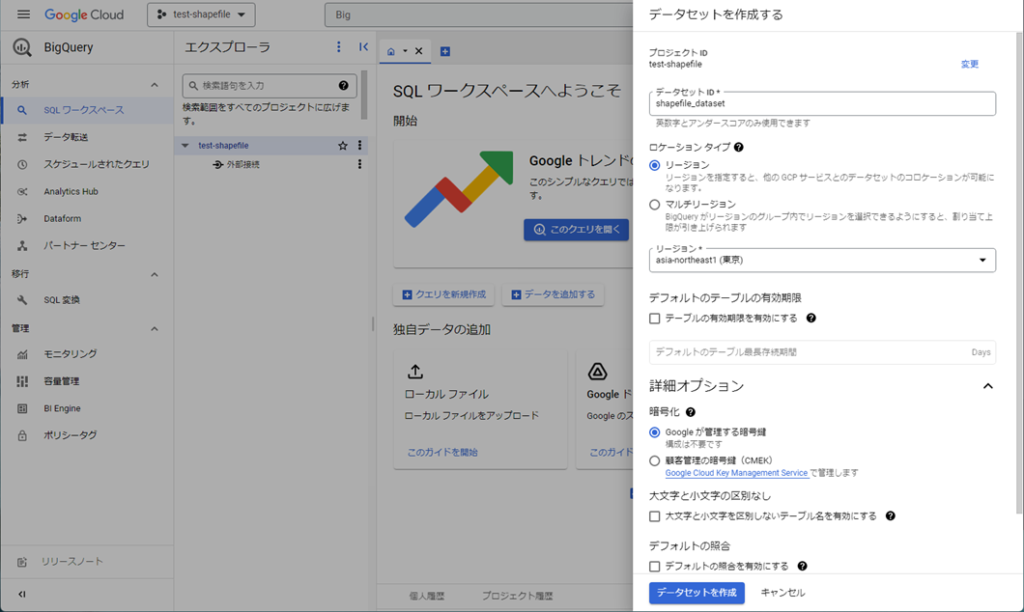
サービスアカウントを作成する
次にBigQueryを操作するために必要なAPIの認証キーの発行を行います。ナビゲーションメニューを開き、IAMと管理からサービスアカウントを選択します。
サービスアカウントを作成をクリックします。
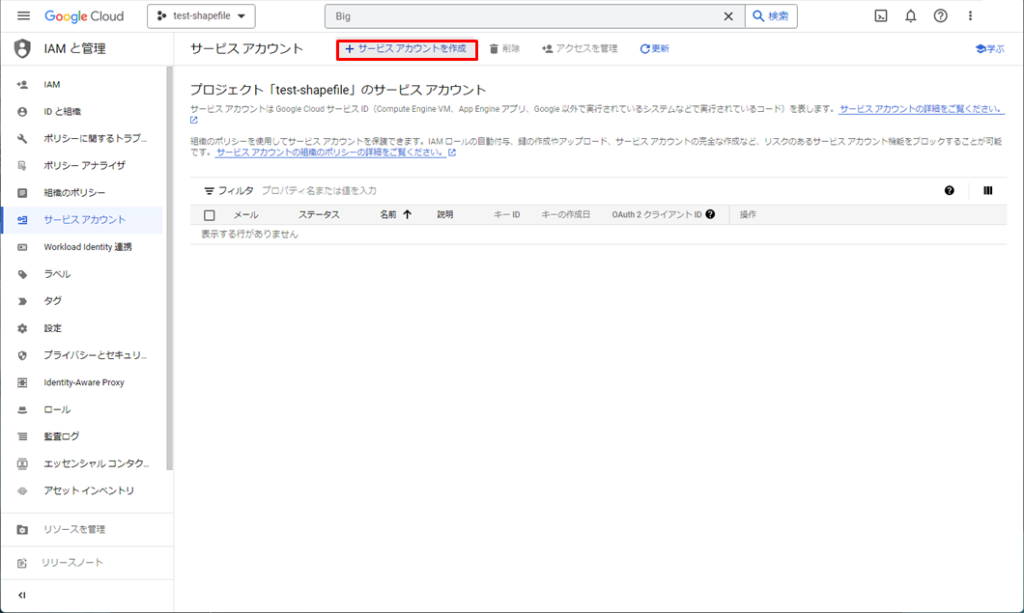
「サービスアカウント名」と「サービスアカウントID」を入力し、「作成して実行」をクリックします。
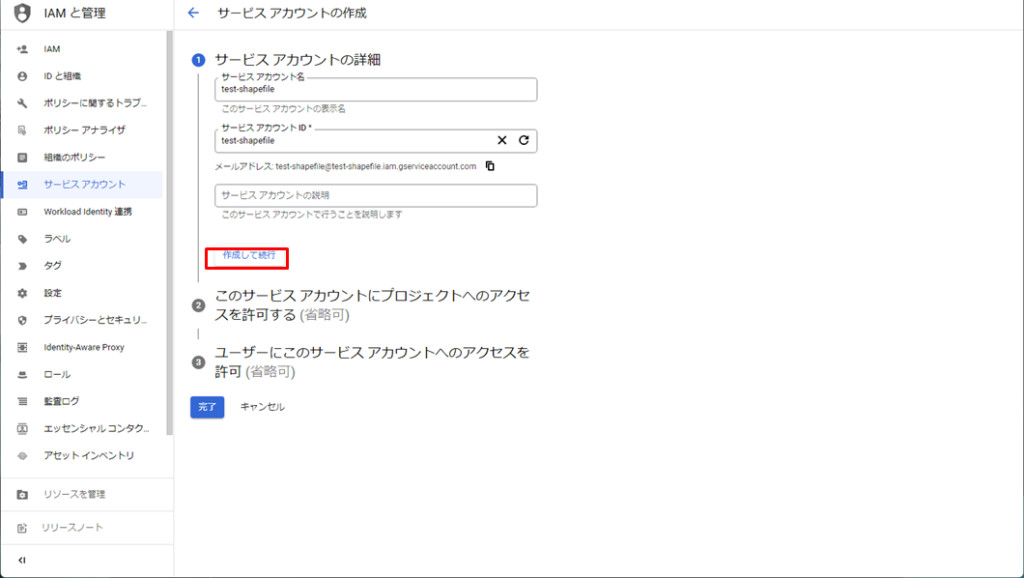
次に作成したサービスアカウントのアクセス権を設定します。「ロールを選択」をクリックし、「BigQuery管理者」を選択します。この操作により、このサービスアカウントからBigQueryの操作が行えるようになりました。/
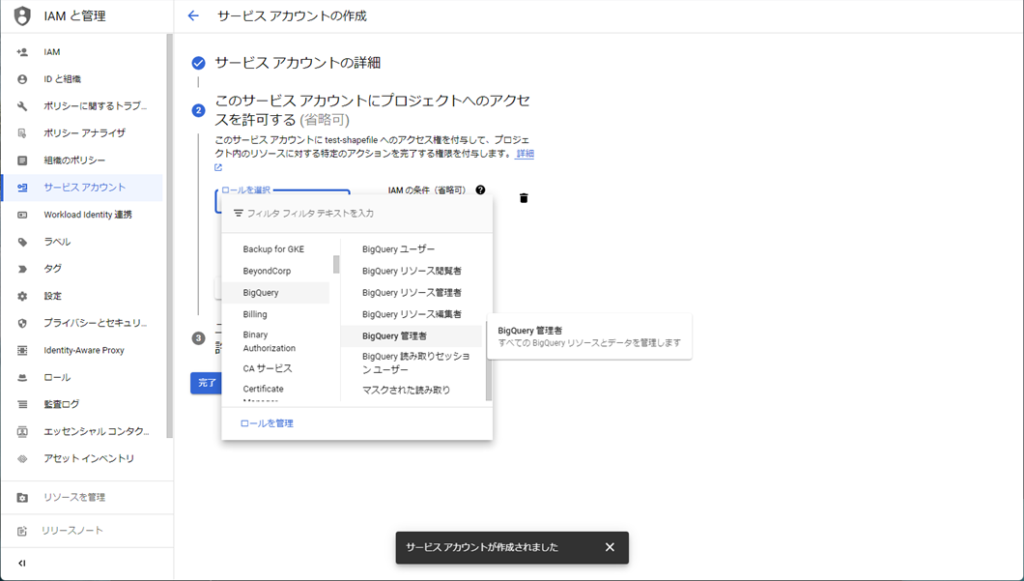
次に作成したサービスアカウントのアクセスキーを発行します。キーのタブを選択し、「鍵を追加」をクリックし、「新しい鍵を作成」をクリックします。
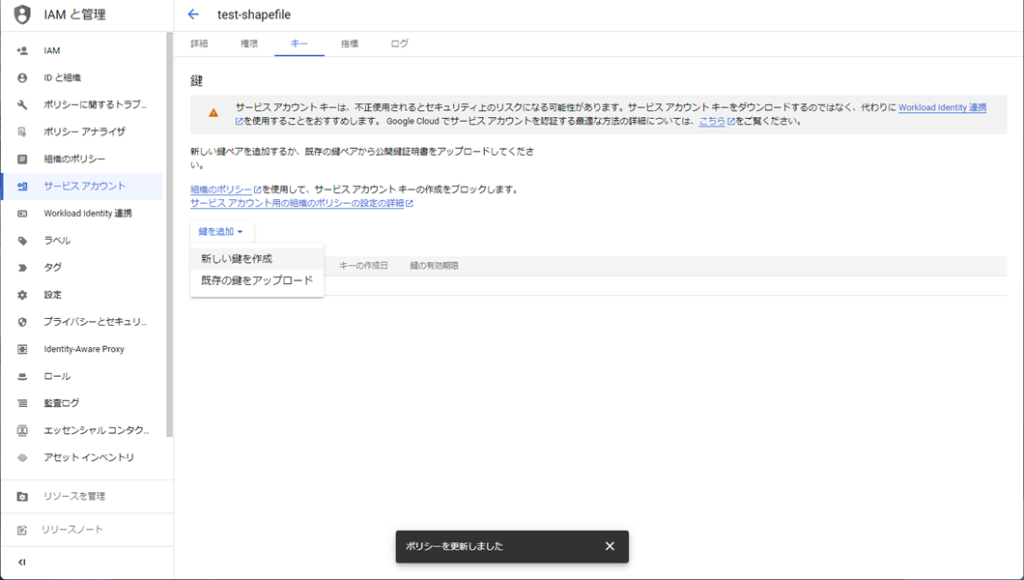
キーのタイプはJSONにチェックを入れ「作成」をクリックします。
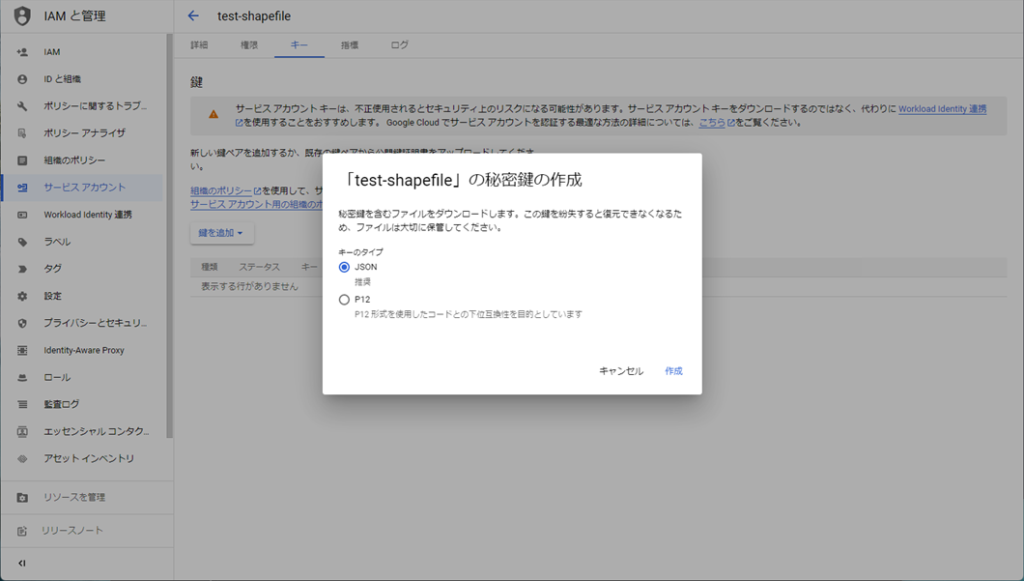
ここで、アクセスキーが記載されたJSONファイルがダウンロードされるので、次に実行するpyファイルと同じフォルダに格納しましょう。
シェープファイルをテーブルに格納する
それでは実際にpythonでコーディングしてみます。
下記のコードをgcp_shapefile.pyという名前でDesktop/labcode/python/ディレクトリに保存します。
import os
import geopandas as gpd
import pandas as pd
from google.cloud import bigquery
from google.oauth2 import service_account
from shapely.geometry import Polygon
# shpファイルの読み込み
shp_file = './shp533940/p533940.shp' # BigQueryテーブルにアップロードするシェープファイルを記載
gdf = gpd.read_file(shp_file)
# geometryの形状の修正
def ensure_outer_shell(polygon):
if polygon.is_empty:
return polygon
if not polygon.exterior.is_ccw:
exterior = Polygon(polygon.exterior.coords[::-1])
interiors = [interior for interior in polygon.interiors]
return Polygon(exterior, interiors)
return polygon
gdf['geometry'] = gdf['geometry'].apply(lambda geom: ensure_outer_shell(geom) if isinstance(geom, Polygon) else geom)
# GeoDataFrameのgeometryをWKT形式に修正し、DataFrameに変換
gdf['geometry'] = gdf['geometry'].apply(lambda x: x.wkt)
df = pd.DataFrame(gdf)
# GCPのBigQuery APIの認証設定
key_path = 'A.json' #作成したアクセスキーのJSONファイルを記載
credentials = service_account.Credentials.from_service_account_file(key_path)
client = bigquery.Client(credentials=credentials, project=credentials.project_id)
# テーブル名とテーブルを作成するデータセットの指定
dataset_id = 'shapefile_dataset'
dataset_ref = client.dataset(dataset_id)
table_id = 'test_shapefile_table' #作成するテーブル名を記載
table_ref = dataset_ref.table(table_id)
schema = [
bigquery.SchemaField("geometry", "GEOGRAPHY") # テーブル内のスキーマを定義
]
# 定義したschemaに基づいてテーブルを作成
table = bigquery.Table(table_ref, schema=schema)
client.create_table(table)
# BigQueryにアップロード
job_config = bigquery.LoadJobConfig(
schema=schema,
# write_disposition="WRITE_TRUNCATE"
)
load_job = client.load_table_from_dataframe(df, table_ref, job_config=job_config)
load_job.result()プログラムを実行する
ターミナルを開き、
$ cd Desktop/labcode/python/
と入力し、ディレクトリを移動します。あとは以下のコマンドを実行するだけです。( $マークは無視してください)
$ python gcp_shapefile.py
実行結果
今回使用したシェープファイルはこちらの記事と同じ環境省生物多様性センターの植生データを利用しました。
GCPコンソールを開き対象のデータセット上に以下のようなテーブルが作成されていれば、成功です。
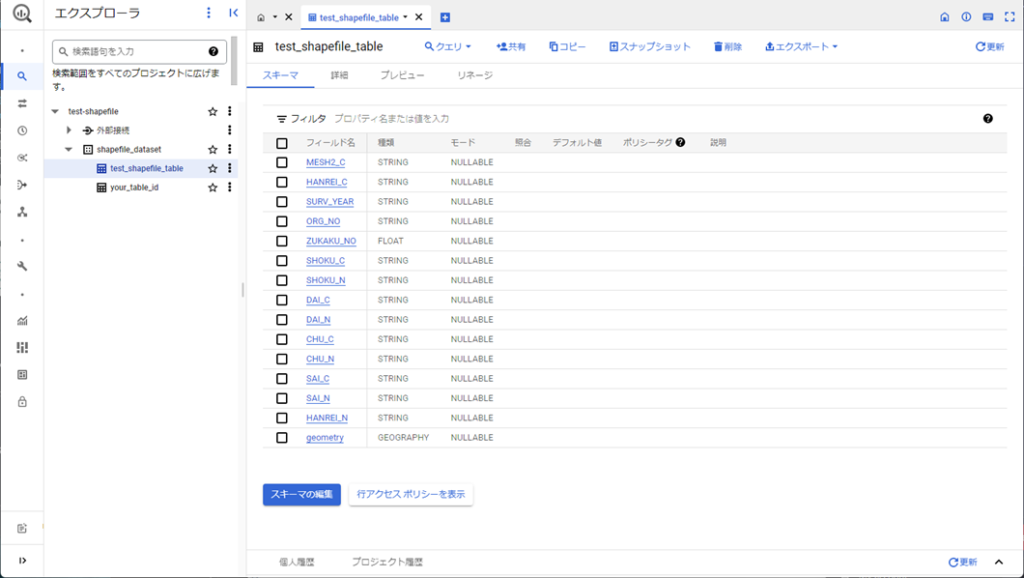
コードの解説
上に書いたソースコードの解説をしていきます。
import os
import geopandas as gpd
import pandas as pd
from google.cloud import bigquery
from google.oauth2 import service_account
from shapely.geometry import Polygon必要なライブラリをインポートします。
from google.cloud import bigqueryは、Google BigQueryサービスとやり取りするために利用します。データセットやテーブルを操作し、クエリの実行などが行えます。
from google.oauth2 import service_accountは、Google Cloud Platform (GCP) のサービスアカウントを使用した認証のためのライブラリで、BigQuery APIへの認証を設定する際に使用されます。
from shapely.geometry import Polygonは、地理空間データの操作や検証に使用するライブラリで、ジオメトリデータの修正や検証を行うために使用されます。
ライブラリが存在しない場合はpipで必要なものをインストールします。また、BigQueryのデータアップロードにpyarrowが必要なため、併せてインストールします。
pip install geopandas pandas google-cloud-bigquery google-auth google-auth-httplib2 shapely
# BigQueryへのデータアップロードに必要なライブラリ
pip install pyarrow
shp_file = './shp533940/p533940.shp' # BigQueryテーブルにアップロードするシェープファイルを記載
gdf = gpd.read_file(shp_file)geopandasライブラリを使用して、シェープファイルをGeoDataFrame(gdf)として格納します。
def ensure_outer_shell(polygon):
if polygon.is_empty:
return polygon
if not polygon.exterior.is_ccw:
exterior = Polygon(polygon.exterior.coords[::-1])
interiors = [interior for interior in polygon.interiors]
return Polygon(exterior, interiors)
return polygon
gdf['geometry'] = gdf['geometry'].apply(lambda geom: ensure_outer_shell(geom) if isinstance(geom, Polygon) else geom)ここでは、GeoDataFramegdf内のポリゴンが反時計回りになるように修正しています。ポリゴンには、頂点の並びが時計回りのものと反時計回りのものが存在します。BigQuery のジオメトリGEOGRAPHY型は反時計回りに揃える必要があるため、この処理を行うことで、後続の処理にエラーが発生しないようになります。
ensure_outer_shell関数:修正対象のポリゴンpolygonに対して、以下の処理を行います。polygon.is_emptyがTrueの場合、そのままのポリゴンを返す。polygon.exterior.is_ccwがFalse(外縁が時計回り)の場合、外縁の頂点座標を反転([::-1])し、interiors(内縁)とともに新しいポリゴンを作成し返す。この処理を行うことで、ドーナツ型のようなリング状のポリゴンに対しても後続の処理が行えるようになります。- それ以外の場合、そのままのポリゴンを返す。
apply(lambda geom: ensure_outer_shell(geom) if isinstance(geom, Polygon) else geom):apply関数を使用して、geometryカラムの各ジオメトリに対して無名関数lambdaを適用します。この無名関数は、ジオメトリがポリゴンisinstance(geom, Polygon)である場合、ensure_outer_shell関数を適用して外縁を反時計回りに修正します。それ以外のジオメトリタイプの場合は、そのままのジオメトリを返します。
gdf['geometry'] = gdf['geometry'].apply(lambda x: x.wkt)
df = pd.DataFrame(gdf)GeoDataFramegdfのジオメトリデータを、Well-Known Text (WKT) 形式の文字列に変換し、その結果を新しいDataFramedfに格納しています。
gdf['geometry'] = gdf['geometry'].apply(lambda x: x.wkt):geometry カラム内のすべてのジオメトリデータに対して、無名関数lambdaを適用して WKT 形式の文字列に変換します。WKT は、ジオメトリデータをテキスト形式で表現する標準的な方法です。この操作により、GeoDataFrame のジオメトリがWKT 形式の文字列データに置き換えられます。
key_path = 'A.json' #作成したアクセスキーのJSONファイルを記載
credentials = service_account.Credentials.from_service_account_file(key_path)
client = bigquery.Client(credentials=credentials, project=credentials.project_id)ここでは、BigQuery API への認証を行っています。
key_path = 'A.json':Google Cloud Platform (GCP) で生成したサービスアカウントキー(JSON 形式のファイル)のパスをkey_path変数に格納します。このキーは、BigQuery API へのアクセス権限を持つサービスアカウントを識別します。service_account.Credentials.from_service_account_file(key_path):key_pathで指定されたサービスアカウントキーを使用して、service_account.Credentialsクラスのインスタンスを生成します。このインスタンスは、BigQuery API への認証に使用されるクレデンシャル情報を保持します。bigquery.Client(credentials=credentials, project=credentials.project_id):bigquery.Clientクラスのインスタンスを生成し、client変数に格納します。このインスタンスは、BigQuery API に対する操作(クエリの実行やテーブルの作成など)を行うためのクライアントオブジェクトです。credentials引数には、先ほど生成したCredentialsインスタンスを渡し、project引数には、サービスアカウントが所属する GCP プロジェクトの ID を指定します。
この処理により、BigQuery API への認証が行われ、以降の処理で BigQuery にアクセスするためのクライアントオブジェクトが生成されます。
dataset_id = 'shapefile_dataset'
dataset_ref = client.dataset(dataset_id)
table_id = 'test_shapefile_table' #作成するテーブル名を記載
table_ref = dataset_ref.table(table_id)
schema = [
bigquery.SchemaField("geometry", "GEOGRAPHY") # テーブル内のスキーマを定義
]
# 定義したschemaに基づいてテーブルを作成
table = bigquery.Table(table_ref, schema=schema)
client.create_table(table)ここでは、BigQueryのデータセットshapefile_dataset内に新しいテーブルtest_shapefile_tableを作成し、そのテーブルにgeometryという名前のGEOGRAPHY型のカラムを持たせるように指定しています。
この処理により、BigQuery に新しいテーブルが作成され、後続の処理でシェープファイルのデータをインポートするための準備が整います。
job_config = bigquery.LoadJobConfig(
schema=schema,
# write_disposition="WRITE_TRUNCATE" # アップロードがうまくいかない場合はこの行のコメントアウトを外す
)
load_job = client.load_table_from_dataframe(df, table_ref, job_config=job_config)
load_job.result()ここでは、DataFramedfに格納されたデータを BigQuery のテーブルにアップロードしています。具体的には、以下の手順で行われます。
bigquery.LoadJobConfig(schema=schema, write_disposition="WRITE_TRUNCATE"):bigquery.LoadJobConfigオブジェクトを作成し、job_config変数に格納します。このオブジェクトは、BigQuery へのデータロードジョブの設定を定義します。schema引数には、先程作成したテーブルのスキーマを指定し、アップロードする対象を指定します。エラーが出る場合は、write_dispositionを実行します。write_dispositionは引数に"WRITE_TRUNCATE"を指定しており、既存のテーブルにデータがある場合、データが上書きされることを指定します。client.load_table_from_dataframe(df, table_ref, job_config=job_config):bigquery.Clientインスタンスclientのload_table_from_dataframeメソッドを使用して、DataFramedfから BigQuery テーブルにデータをアップロードするロードジョブを開始します。table_ref引数には、先程作成した BigQuery テーブルへの参照を指定し、job_config引数には、作成したロードジョブ設定を指定します。このメソッドは、BigQuery へのデータロードジョブを実行し、ジョブオブジェクトbigquery.job.LoadJobを返します。また、load_table_from_dataframeメソッドでは、job_configでschemaとして指定していないカラムがDataFramedfに含まれている場合、スキーマを自動で推定しアップロードします。load_job.result():result()メソッドを使用して、データロードジョブの完了を待ちます。このメソッドは、ジョブが完了するまでブロックし、ジョブが成功した場合はジョブ結果を返します。エラーや例外が発生した場合、このメソッドは例外を送出します。
このコードにより、シェープファイルのデータが BigQuery のテーブルにアップロードされます。
最後に
ここまででシェープファイルをBigQueryのテーブルに格納する方法を紹介しました。シェープファイルやcsvファイルでは、大量の地理情報を扱う際のデータスケーラビリティが劣ります。しかし、BigQueryを利用することでこれらを改善できます。
次の記事ではBigQueryを利用して衛星データを入手する方法を紹介します。
Pythonを使った衛星データ解析の初心者向け技術書を販売中!
¥2,500 → ¥800 今なら約70%OFF!!
Google Earth Engineを使えば簡単に
自宅にいながら地球環境の変動を観察できます

