
バーグラフを描画したい、折れ線グラフを描画したい、、etc と思ったときに、それぞれのグラフを描画しやすい形に生データを整形したデータ(ファイル)が必要になります。そんなときに、自分で自由にデータ整形ができるとデータ解析の幅が広がりますし、自分が表現したいようにグラフを描画することができるようになります。
今回は、マップ上にバーグラフを表示するために必要なデータファイルの整形の方法をご紹介します!Pythonを使ったデータの操作方法を学びましょう。
macOS Monterey(12.4), python3.7.10

研究で使えるPythonデータ解析の初心者向け技術書を販売中
¥1,000 → ¥500 今なら50%OFF!!
プログラミングで生産性が向上!
著者が実際に研究で使用していたノウハウを凝縮

Streamlitで作るデータ解析Webアプリの技術書を販売中
¥2,000 → ¥1,000 今なら50%OFF!!
データ解析をアプリで行う!
データ解析とグラフ描画を自動でしてくれるアプリが作れます!
データ整形の目的
描画したいバーグラフ
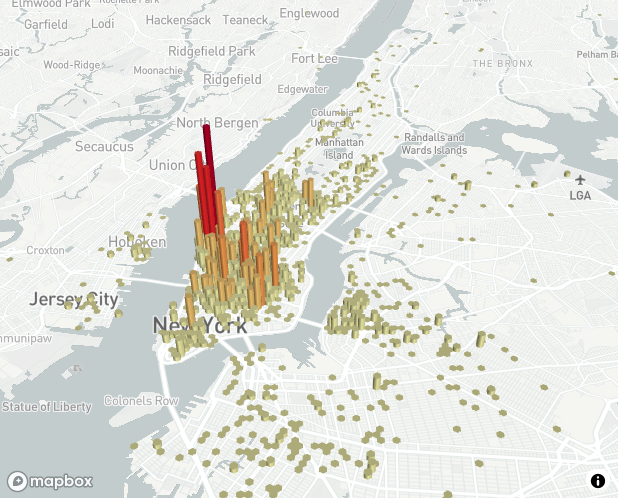
Streamlitというpythonのライブラリを用いて、地図上にバーグラフを表示させたいと考えています。バーは何かしらの回数・個数(カウント)を表しています。上図はニューヨークにおけるUberEatsの利用回数を表したものです。
今回は、2020年9月~2022年9月の間において、1日の積算降水量が50mmを超えた日数がどれくらいあるかを地図上にバーグラフで描画したいと思います。 降水量の観測範囲は大阪府に絞りたいと思います。
地図上にバーグラフを表示させるためには、前段階でデータ整形を行う必要があり、次のようなデータファイルの作成が必要になります。
データ整形後のデータファイルと整形前のデータファイル(生データ)
整形後のデータファイル
以下のようなコンマ(,)で分けられたCSV(Comma Separated Values)データが必要になります。 左から順に日付、地点名、緯度、経度、降水量のデータが並べています。 (ここでの緯度・経度は10進数)
実は、地図上にバーグラフを表示する上で最低限必要なデータは実は緯度、経度だけです。 Streamlitでは、一行一行を1カウントと見積もってくれるので、同じ緯度・経度の地点を内部で勝手に積算して描画してくれます。
日付と地点名と降水量はグラフの描画には不要ですが、あとでデータを見返したときに何が何か全くわからなくなってしまうので記載しています。このあたりは研究で用いるデータ解析のお作法的なものです。
このようなデータが格納されたCSVファイルを生データを整形して作成することが本記事のゴールになります。
# 日付, 地点名, 緯度, 経度, 降水量(mm)
2020/9/25,大阪,34.6817,135.5183,64.0
2020/9/25,豊中,34.7833,135.4383,62.0
2020/9/25,能勢,34.9483,135.455,75.0
2020/9/25,茨木,34.86,135.56,56.5
2020/9/25,枚方,34.8083,135.6717,65.5
2020/9/25,生駒山,34.675,135.6767,59.5
2020/9/25,堺,34.555,135.485,52.5
2020/9/25,八尾,34.5967,135.6,53.5
2020/9/25,河内長野,34.4233,135.5433,53.0
2020/9/25,熊取,34.385,135.35,54.0
2020/10/8,河内長野,34.4233,135.5433,57.0
2020/10/9,大阪,34.6817,135.5183,55.5
2020/10/9,生駒山,34.675,135.6767,67.0
2020/10/9,堺,34.555,135.485,62.5
2020/10/9,八尾,34.5967,135.6,53.0
2020/10/9,河内長野,34.4233,135.5433,76.5
2020/10/9,熊取,34.385,135.35,72.0
2020/10/10,生駒山,34.675,135.6767,55.0
2020/10/23,河内長野,34.4233,135.5433,61.0
2020/10/23,熊取,34.385,135.35,50.5
2021/3/21,茨木,34.86,135.56,57.5
2021/3/21,枚方,34.8083,135.6717,50.5
2021/4/17,大阪,34.6817,135.5183,59.5
2021/4/17,枚方,34.8083,135.6717,58.5
2021/4/29,大阪,34.6817,135.5183,105.0
2021/4/29,豊中,34.7833,135.4383,96.5
...生データ
気象庁のサイトから過去の降水量のデータをダウンロードしてくることが可能です。 一度にダウンロードできるデータ量に上限があるので、今回は地域を大阪、期間を約3年間にしぼっています。
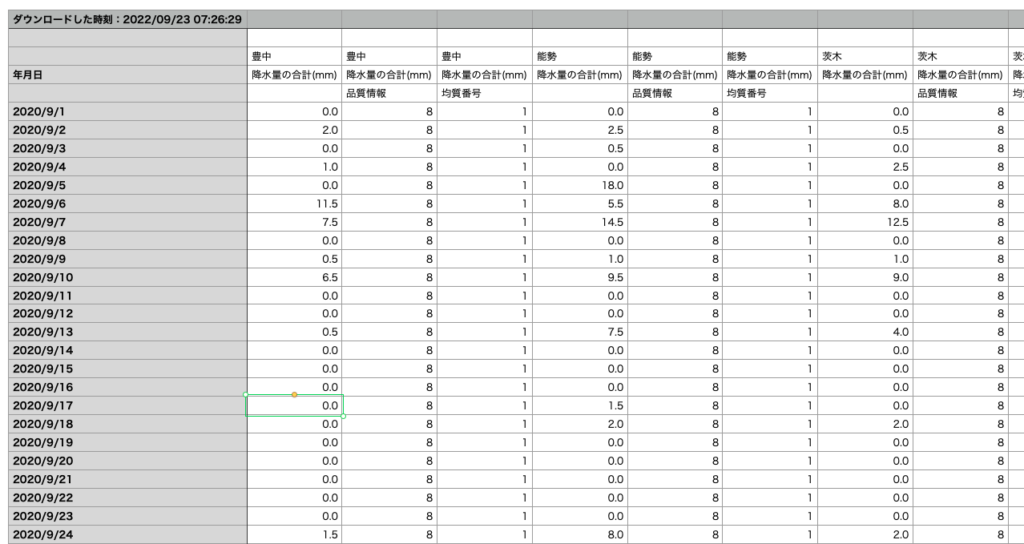
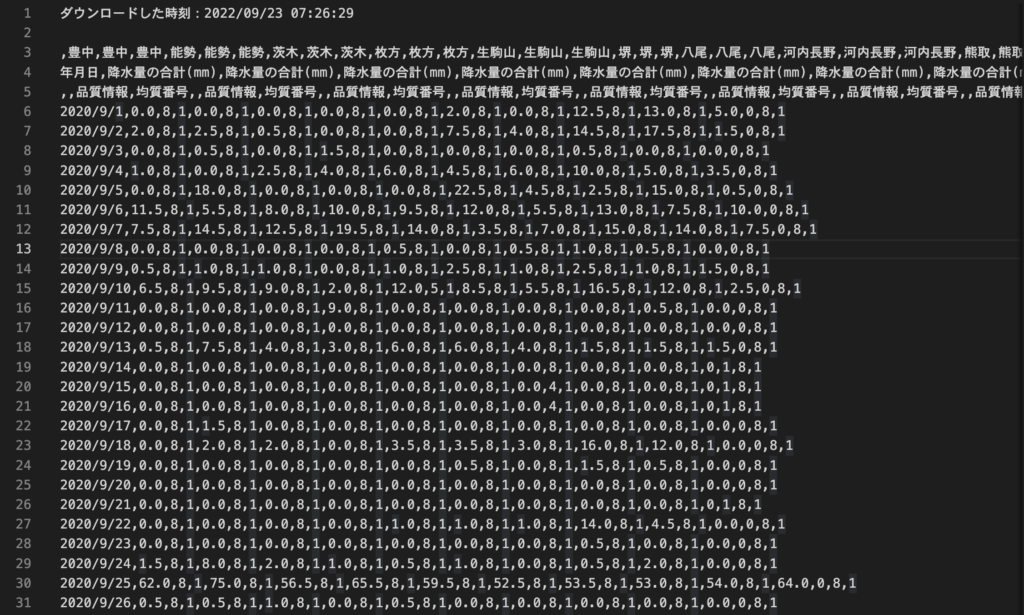
ダウンロードしてきたデータは以下のようなCSVファイルになっています。上がスプレッドシートで見た時の状態で、下がテキストエディタで表示したときの状態です。 ずらーっと降水量のデータが並んでいますが、今回必要としない情報も混じったデータファイルとなっており、必要とするデータの形式とは程遠いことがわかります。このデータを頑張って、上でお見せした形式に変換していきます。
手始めに、ダウンロードしてきたCSVファイルを osaka_precipitation_202009_202209.csvという名前で Desktop/labcode/python/web-data-analysis/data_format ディレクトリに保存します。
緯度・経度の情報
地図上にプロットするので緯度・経度の情報が必要です。 今回使用する降水量のデータはアメダスで計測したものなので、アメダスの設置箇所の緯度・経度の情報を入手する必要があります。
アメダスの緯度・経度の情報は気象庁が提供しているこちらの資料から取得してきました。

今回はこれに書かれているデータを以下のようにAMeDAS_LATITUDE_LONGITUDE.csvという名前のCSVファイルとして扱います。(このファイルは手作業で作成しました。) このCSVファイルも Desktop/labcode/python/web-data-analysis/data_format ディレクトリに保存します。
ここでの緯度・経度は60進数(度・分)になっています。なので、10進数に変換する必要があります。
# 都道府県, 観測所名, 緯度(度), 緯度(分), 経度(度),経度(分)
大阪,能勢,34,56.9,135,27.3
大阪,茨木,34,51.6,135,33.6
大阪,枚方,34,48.5,135,40.3
大阪,豊中,34,47.0,135,26.3
大阪,大阪,34,40.9,135,31.1
大阪,生駒山,34,40.5,135,40.6
大阪,堺,34,33.3,135,29.1
大阪,八尾,34,35.8,135,36.0
大阪,関空島,34,26.0,135,13.9
大阪,河内長野,34,25.4,135,32.6
大阪,熊取,34,23.1,135,21.0データファイルの整形方法
データ整形用のプログラムを実装する際のコツですが、手作業でやるとしたらどうやるかをまず考えることです。 もし、エクセルなどのスプレッドシート上で手作業で数値を並べ替えるとすると、どうやるかを考える、もしくは実際に手を動かしてみると実装のイメージが湧きやすくなります。 プログラムはその手作業で行う操作を単に自動化させたものにすぎないからです。
ソースコード
以下のように、numpyというライブラリを使って実装します。
以下のコードをdata_format.py という名前で Desktop/labcode/python/web-data-analysis/data_format ディレクトリに保存します。
import numpy as np
# 生データを読み込む。データファイルの内容をリストに格納。
data_file = 'osaka_precipitation_202009_202209.csv'
# ダウンロードしてきたファイルによっては、地点の順番は異なるので注意。気象庁のデータファイルのエンコードはshift-jisなことに注意。
dates, precs_toyonaka, precs_nose, precs_ibaraki, precs_hirakata, precs_ikoma \
, precs_sakai, precs_yao, precs_kawachinagano, precs_kumatori, precs_osaka \
= np.loadtxt(data_file,
delimiter=',',
dtype=str,
skiprows=5,
usecols=(0, 1, 4, 7, 10, 13, 16, 19, 22, 25, 29),
unpack=True,
encoding="shift-jis")
# アメダスの緯度・経度情報を読み込む。緯度・経度情報をリストに格納。
location_refarence_data = 'AMeDAS_LATITUDE_LONGITUDE.csv'
location_names, lat_degs, lat_mins, lon_degs, lon_mins = np.loadtxt(location_refarence_data,
delimiter=',',
dtype=str,
skiprows=1,
usecols=(1, 2, 3, 4, 5),
unpack=True,
encoding="utf-8")
# 緯度・経度の辞書を作成。緯度・経度は10進数に変換。
lat_dict = dict()
lon_dict = dict()
for i, location_name in enumerate(location_names):
lat_dict.update(
{f"{location_name}": round(float(lat_degs[i]) + float(lat_mins[i]) / 60, 4)}
)
lon_dict.update(
{f"{location_name}": round(float(lon_degs[i]) + float(lon_mins[i]) / 60, 4)}
)
# ファイルの出力。データの整形をここで行う。
with open('map_data.csv', 'w') as outfile:
outfile.write('# 日付, 地点名, 緯度, 経度, 降水量(mm)\n')
criteria: float = 50.0
for date, prec_toyonaka, prec_nose, prec_ibaraki, prec_hirakata, prec_ikoma, prec_sakai, \
prec_yao, prec_kawachinagano, prec_kumatori, prec_osaka \
in zip(dates, precs_toyonaka, precs_nose, precs_ibaraki, precs_hirakata, precs_ikoma, precs_sakai, precs_yao,
precs_kawachinagano, precs_kumatori, precs_osaka):
if float(prec_toyonaka) > criteria:
outfile.write(f"{date},豊中,{lat_dict['豊中']},{lon_dict['豊中']},{prec_toyonaka}\n")
if float(prec_nose) > criteria:
outfile.write(f"{date},能勢,{lat_dict['能勢']},{lon_dict['能勢']},{prec_nose}\n")
if float(prec_ibaraki) > criteria:
outfile.write(f"{date},茨木,{lat_dict['茨木']},{lon_dict['茨木']},{prec_ibaraki}\n")
if float(prec_hirakata) > criteria:
outfile.write(f"{date},枚方,{lat_dict['枚方']},{lon_dict['枚方']},{prec_hirakata}\n")
if float(prec_ikoma) > criteria:
outfile.write(f"{date},生駒山,{lat_dict['生駒山']},{lon_dict['生駒山']},{prec_ikoma}\n")
if float(prec_sakai) > criteria:
outfile.write(f"{date},堺,{lat_dict['堺']},{lon_dict['堺']},{prec_sakai}\n")
if float(prec_yao) > criteria:
outfile.write(f"{date},八尾,{lat_dict['八尾']},{lon_dict['八尾']},{prec_yao}\n")
if float(prec_kawachinagano) > criteria:
outfile.write(f"{date},河内長野,{lat_dict['河内長野']},{lon_dict['河内長野']},{prec_kawachinagano}\n")
if float(prec_kumatori) > criteria:
outfile.write(f"{date},熊取,{lat_dict['熊取']},{lon_dict['熊取']},{prec_kumatori}\n")
if float(prec_osaka) > criteria:
outfile.write(f"{date},大阪,{lat_dict['大阪']},{lon_dict['大阪']},{prec_osaka}\n")現状のフォルダ内の様子は以下のようになっているはずです。
/data_format
|_ osaka_precipitation_202009_202209.csv // 降水量の生データ
|_ AMeDAS_LATITUDE_LONGITUDE.csv // 緯度・経度の情報が入ったファイル
|_ data_format.py // データ整形用コードプログラムを実行する
ターミナルを開き、
$ cd Desktop/labcode/python/web-data-analysis/data_formatと入力し、ディレクトリを移動します。あとは以下のコマンドを実行するだけです。( $マークは無視してください)
$ python data_format.pyすぐに map_data.csv というファイルが作成され、フォルダ内は下のような状態になっていると思います。
/data_format
|_ osaka_precipitation_202009_202209.csv // 降水量の生データ
|_ AMeDAS_LATITUDE_LONGITUDE.csv // 緯度・経度の情報が入ったファイル
|_ data_format.py // データ整形用コード
|_ map_data.csv // NEW!!numpyのインストール方法
ライブラリをインターネット上から自身のPCにダウンロードしていないと、 たとえ import numpy as npと 記述しても使えません。 numpyがないよ!という旨のエラーが出た場合は、pip installを使ってダウンロードしましょう。実行するディレクトリはどこでもOKです。
$ pip install numpy しばらくして、Successfullyという文言が出て来れば完了です。
余談(けっこう重要)
お気づきの方もいらっしゃるかもしれませんが、データ整形を行うにあたって、生データのファイルは一切変更をかけていません。データ解析において、生データに手を加えることはご法度です。生データはデータ解析における命です。ここを修正してしまうと後でデータの検証を行う際に、計測に問題があったのか、解析に問題があったのかの判断が全くできなくなってしまいます。
生データは参照するだけにとどめ、グラフ描画用のデータファイルを作成することを肝に銘じましょう。
コードの解説
上に書いたソースコードの解説をしていきます。
import numpy as np
# 生データを読み込む。データファイルの内容をリストに格納。
data_file = 'osaka_precipitation_202009_202209.csv'
# ダウンロードしてきたファイルによっては、地点の順番は異なるので注意。気象庁のデータファイルのエンコードはshift-jisなことに注意。
dates, precs_toyonaka, precs_nose, precs_ibaraki, precs_hirakata, precs_ikoma \
, precs_sakai, precs_yao, precs_kawachinagano, precs_kumatori, precs_osaka \
= np.loadtxt(data_file,
delimiter=',',
dtype=str,
skiprows=5,
usecols=(0, 1, 4, 7, 10, 13, 16, 19, 22, 25, 29),
unpack=True,
encoding="shift-jis")numpyの loadtxt関数を用いて、生データの各列の情報を各変数に格納しています。 詳しい解説は過去の記事に譲ります。
dates 変数にはリスト型で ['2020/9/1' '2020/9/2' ... '2022/9/22'] とデータが入っています。 print(dates)と書いて出力すると見れますよ。
precs_toyonaka 変数には同じくリスト型で ['0.0' '2.0' '0.0' ..., '2.5'] と降水量のデータが入っています。 他の変数は別の地点の降水量のデータが入っています。
usecols=(0, 1, 4, 7, 10, 13, 16, 19, 22, 25, 29) はデータファイルの列を指定しており、各列の情報が左辺に列挙している変数にそれぞれ格納されています。
# アメダスの緯度・経度情報を読み込む。緯度・経度情報をリストに格納。
location_refarence_data = 'AMeDAS_LATITUDE_LONGITUDE.csv'
location_names, lat_degs, lat_mins, lon_degs, lon_mins = np.loadtxt(location_refarence_data,
delimiter=',',
dtype=str,
skiprows=1,
usecols=(1, 2, 3, 4, 5),
unpack=True,
encoding="utf-8")ここも上と同様にnumpyの loadtxt関数を用いて、緯度・経度の情報を各変数に格納しています。
# 緯度・経度の辞書を作成。緯度・経度は10進数に変換。
lat_dict = dict()
lon_dict = dict()
for i, location_name in enumerate(location_names):
lat_dict.update(
{f"{location_name}": round(float(lat_degs[i]) + float(lat_mins[i]) / 60, 4)}
)
lon_dict.update(
{f"{location_name}": round(float(lon_degs[i]) + float(lon_mins[i]) / 60, 4)}
)各地名と緯度・経度の情報を扱いやすいように辞書にまとめる作業と、60進数から10進数への変換を行なっています。
Pythonには辞書型というデータ形式が存在します。JavaScriptなどではjson型と呼ばれるものに相当します。下のようなデータ形式のことです。
{
'能勢': 135.455,
'茨木': 135.56,
'枚方': 135.6717,
'豊中': 135.4383,
'大阪': 135.5183,
'生駒山': 135.6767,
'堺': 135.485,
'八尾': 135.6,
'関空島': 135.2317,
'河内長野': 135.5433,
'熊取': 135.35
}例えば、 lon_dict という名前の経度情報をまとめた辞書から 堺の経度を取り出したいときはlon_dict['堺'] のように表記するだけでよいのです。 辞書として情報を1箇所に集約させることでデータを扱いやすくしています。
また、 for i, location_name in enumerate(location_names): ですが、これはpythonのforループの応用的な使い方になります。 普通は for location_name in location_names: のようにenumerate は用いずにループを回しますが、インデックスの値(リストの何番目か)も欲しいときは、enumerate 関数を用いて上のような書き方をします。インデックスの値はi に格納されています。
# ファイルの出力。データの整形をここで行う。
with open('map_data.csv', 'w') as outfile:
outfile.write('# 日付, 地点名, 緯度, 経度, 降水量(mm)\n')
criteria: float = 50.0
for date, prec_toyonaka, prec_nose, prec_ibaraki, prec_hirakata, prec_ikoma, prec_sakai, \
prec_yao, prec_kawachinagano, prec_kumatori, prec_osaka \
in zip(dates, precs_toyonaka, precs_nose, precs_ibaraki, precs_hirakata, precs_ikoma, precs_sakai, precs_yao,
precs_kawachinagano, precs_kumatori, precs_osaka):
if float(prec_toyonaka) > criteria:
outfile.write(f"{date},豊中,{lat_dict['豊中']},{lon_dict['豊中']},{prec_toyonaka}\n")
if float(prec_nose) > criteria:
outfile.write(f"{date},能勢,{lat_dict['能勢']},{lon_dict['能勢']},{prec_nose}\n")
if float(prec_ibaraki) > criteria:
outfile.write(f"{date},茨木,{lat_dict['茨木']},{lon_dict['茨木']},{prec_ibaraki}\n")
if float(prec_hirakata) > criteria:
outfile.write(f"{date},枚方,{lat_dict['枚方']},{lon_dict['枚方']},{prec_hirakata}\n")
if float(prec_ikoma) > criteria:
outfile.write(f"{date},生駒山,{lat_dict['生駒山']},{lon_dict['生駒山']},{prec_ikoma}\n")
if float(prec_sakai) > criteria:
outfile.write(f"{date},堺,{lat_dict['堺']},{lon_dict['堺']},{prec_sakai}\n")
if float(prec_yao) > criteria:
outfile.write(f"{date},八尾,{lat_dict['八尾']},{lon_dict['八尾']},{prec_yao}\n")
if float(prec_kawachinagano) > criteria:
outfile.write(f"{date},河内長野,{lat_dict['河内長野']},{lon_dict['河内長野']},{prec_kawachinagano}\n")
if float(prec_kumatori) > criteria:
outfile.write(f"{date},熊取,{lat_dict['熊取']},{lon_dict['熊取']},{prec_kumatori}\n")
if float(prec_osaka) > criteria:
outfile.write(f"{date},大阪,{lat_dict['大阪']},{lon_dict['大阪']},{prec_osaka}\n")冒頭2行の with open('map_data.csv', 'w') as outfile: outfile.write('# 日付, 地点名, 緯度, 経度, 降水量(mm)\\n') でmap_data.csv を作成し、 そのファイルの内容として # 日付, 地点名, 緯度, 経度, 降水量(mm)\\n を記述しています。 ファイルの書き出しについての解説は、過去の記事に譲ります。
for <変数1>, <変数2> in zip(<リスト1>, <リスト2>): のように zip関数を用いると、2つ以上のリストを用いて同時にループを回せます。今回は各地点の降水量のリストを同時に用いたいので、長い記述がされています。
if float(prec_toyonaka) > criteria: は、降水量が50mm以上となる場合だけ、データファイルに出力されるように条件分岐を設けています。 criteria: float = 50.0 の数値を調整して、出力されるファイルがどのように変わるか試してみてください。
最後に
numpyというpythonのライブラリを用いて生データを必要な形式のデータファイルに整形する方法を紹介しました。 データ解析を行う上で、今回紹介したようなデータ整形は非常によく使いますので、こういったプログラムをテキパキと書けるようになるとできるアナリストという感じがしますね。
次回は、今回データ整形して作成したCSVファイルを読み込んで、MAP上にバーグラフを表示する方法をご紹介したいと思います。
研究で使えるPythonデータ解析の初心者向け技術書を販売中
¥1,000 → ¥500 今なら50%OFF!!
プログラミングで生産性が向上!
著者が実際に研究で使用していたノウハウを凝縮
Streamlitで作るデータ解析Webアプリの技術書を販売中
¥2,000 → ¥1,000 今なら50%OFF!!
データ解析をアプリで行う!
データ解析とグラフ描画を自動でしてくれるアプリが作れます!

