
これまで、Google Earth Engine (以下GEE)を利用した衛星データの主な利用方法について紹介してきましたが、発展させて機械学習を利用した解析について紹介します。
機械学習を利用することで衛星データから土地被覆分類や時系列予測などができるようになります。
今回その中でも土地被覆分類によく利用されるランダムフォレスト法をGEEを使って紹介します。
Python 3.11.4, earthengine-api 0.1.377

Pythonを使った衛星データ解析の初心者向け技術書を販売中!
¥2,500 → ¥800 今なら約70%OFF!!
Google Earth Engineを使えば簡単に
自宅にいながら地球環境の変動を観察できます
土地被覆分類とは?
衛星画像や航空写真などのリモートセンシングデータを分析し、地表のさまざまなカバータイプ(例えば、森林、農地、水域、都市地域など)を識別するプロセスです。土地被覆分類は地球環境のモニタリング、土地利用計画、生態系の管理、気候変動の研究など、多くの応用分野で利用されます。
以前の記事で利用した環境省生物多様性センターの植生図をはじめ、国土地理院の地理院地図、産総研のシームレス地質図などが作成され公開されています。
GEEには土地被覆分類を行うためのオブジェクトとしてee.Classifierというものが用意されています。これを利用することで機械学習を利用した土地被覆分類を行うことができます。
ee.Classifierが対応している主要な機械学習モデルは以下の通りです。
- 決定木(Decision Tree):条件分岐によってグループに分けられる木の構造をしたものです。回帰に使える回帰木、分類に使える分類木を総称したものです。
- ロジスティック回帰:線形回帰の一種で、従属変数が二値の場合に使用されます。出力は確率として解釈され、特定のクラスにデータポイントが属する確率を予測します。
- サポートベクターマシン (SVM):データを高次元空間にマッピングし、その空間で最適な境界線を見つけることで、クラスを分離します。
- ナイーブベイズ:ベイズの定理に基づいた確率的分類器で、特徴間の強い独立性を仮定しています。
- ランダムフォレスト:複数の決定木を組み合わせて予測を行うアンサンブル学習の一種です。各決定木の結果を多数決や平均化することで、一つの最終的な予測を得ます。
今回は、ランダムフォレストを利用して、ローカルな土地被覆分類を行ってみます。
ランダムフォレストとは?
ランダムフォレストとは、教師あり学習アルゴリズムの一種で、分類や回帰の問題を解くために使用されます。この方法はアンサンブル学習の一形態であり、多数の決定木を組み合わせて全体のモデルの性能を向上させます。
以下がランダムフォレストの主な特徴です。
- 決定木とアンサンブル学習: ランダムフォレストは、「決定木」と「アンサンブル学習(バギング)」という2つの手法を組み合わせたアルゴリズムです。決定木は、Yes/Noなど二者択一の質問を階層構造的につなげて、1つずつ答えていくことで最終的に正解にたどり着ける仕組みを持ちます。アンサンブル学習は、より良い予測結果を得るために、複数の学習アルゴリズムを組み合わせる技術です。
- バギング: バギングは、アンサンブル学習の一つで、元データから一部のデータを復元抽出してサンプリングし、複製されたデータセットごとに学習器を生成します。
- 過学習のリスク低減: これらのランダム化プロセスによって、個々の決定木がデータの特定の部分に過度に適合することを防ぎ、モデル全体としてはより一般化された予測を行うことが可能です。
- 柔軟性: 欠損データの扱いやカテゴリ変数の扱いが容易であり、多くの種類のデータセットに対して効果的です。
- 特徴の重要性の評価: 予測において各特徴がどの程度重要かを評価することができます。
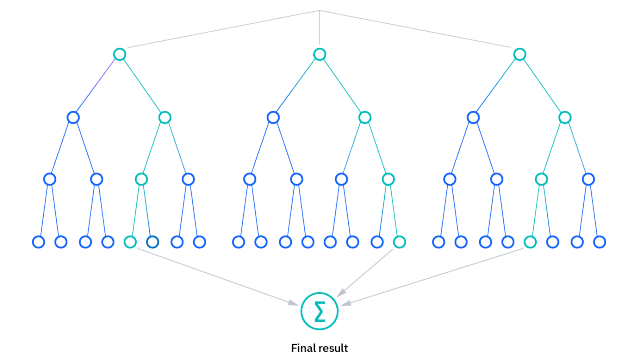
ref: What is Random Forest? | IBM
GEEでのランダムフォレストによる土地被覆分類の実装
コードは以下のように実装しました。今回はgeemapというライブラリを使う関係でJupyterLab上で実行します。
ESAのWorldCoverというデータセットを教師データとして、函館市付近の土地被覆分類を行ってみます。
import ee
import geemap
ee.Initialize()
# Sentinel-2の表面反射率イメージの読み込み
img = ee.Image('COPERNICUS/S2_SR_HARMONIZED/20200417T012649_20200417T013323_T54TVM') \
.select('B.*')
# ESAのWorldCoverデータセットを使用
lc = ee.Image('ESA/WorldCover/v100/2020')
# 土地被覆クラスのリマッピング
class_values = [10, 20, 30, 40, 50, 60, 70, 80, 90, 95, 100]
remap_values = ee.List.sequence(0, 10)
label = 'lc'
lc = lc.remap(class_values, remap_values).rename(label).toByte()
# データセットの結合
sample_img = img.addBands(lc)
# トレーニングデータのサンプリング
roi = ee.Geometry.Rectangle([140.625, 41.721, 140.868, 41.862])
sample = sample_img.stratifiedSample(
numPoints=5000,
classBand=label,
region=roi,
scale=10,
geometries=True
)
# データセットをトレーニングセットとバリデーションセットに分割
sample = sample.randomColumn()
training_sample = sample.filter('random <= 0.8')
validation_sample = sample.filter('random > 0.8')
# 分類器のトレーニング
trained_classifier = ee.Classifier.smileRandomForest(10).train(
features=training_sample,
classProperty=label,
inputProperties=img.bandNames()
)
# トレーニングサンプルの精度評価
train_accuracy = trained_classifier.confusionMatrix()
print('Training accuracy:', train_accuracy.accuracy().getInfo())
# バリデーションサンプルの分類と精度評価
validation_sample = validation_sample.classify(trained_classifier)
validation_accuracy = validation_sample.errorMatrix(label, 'classification')
print('Validation accuracy:', validation_accuracy.accuracy().getInfo())
# イメージの分類
classified_img = img.classify(trained_classifier)
# レイヤーの色パレットの設定
class_vis = {
'min': 0,
'max': 10,
'palette': [
'006400',
'ffbb22',
'ffff4c',
'f096ff',
'fa0000',
'b4b4b4',
'f0f0f0',
'0064c8',
'0096a0',
'00cf75',
'fae6a0',
],
}
# 地図の作成とレイヤーの追加
m = geemap.Map()
m.set_center(140.75, 41.79, 12)
m.addLayer(classified_img, class_vis, 'Classified')
m実行結果
まず、Accuracy(精度)を確認します。今回は以下のようになりました。

これらの値については以下の通りです。
- トレーニング精度(Training accuracy): 約96.53%
- これは、トレーニングデータセットに対する分類器の性能を示しており、分類器がトレーニング中に使用したデータをどれだけうまく分類できたかを意味します。
- 一般に、トレーニング精度が高いことは良いことですが、過剰適合(オーバーフィッティング)の可能性も考慮する必要があります。これは、モデルがトレーニングデータに対して過度に最適化されており、新しい未知のデータに対してはうまく機能しない状況を指します。
- バリデーション精度(Validation accuracy): 約72.7%
- バリデーション精度は、トレーニングに使用されていないデータ(バリデーションデータセット)に対する分類器の性能を示します。
- バリデーション精度が低い場合、モデルの一般化能力に問題があるか、データセットの特徴が十分でない可能性があります。
Accuracy(精度)の確認が完了し、問題ない場合は作成した土地被覆分類図を確認します。
今回は以下のような地図が表示されていれば成功です。
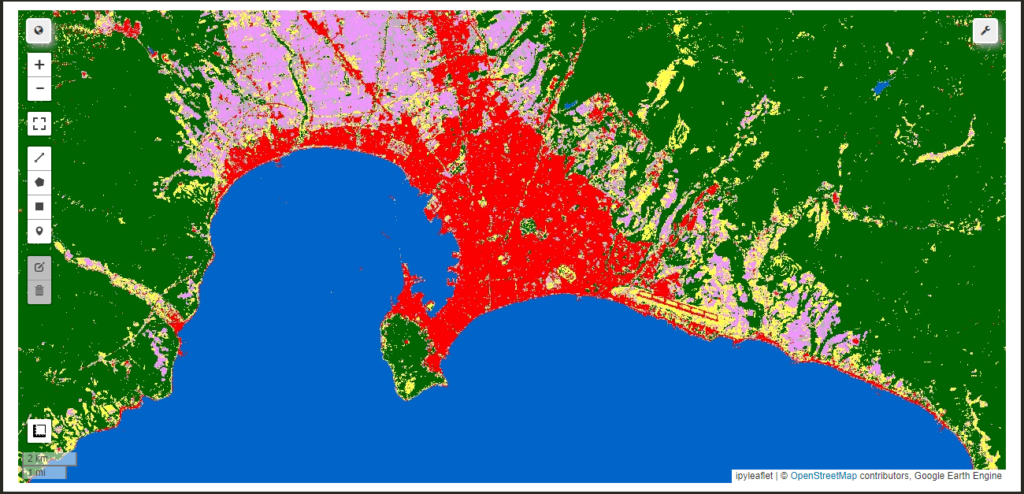
緑色が植生、赤色が市街地、灰色が建造物など、黄色が裸地や砂地、ピンクが農地、青が水域に分類されています。
コードの解説
上に書いたソースコードの解説をしていきます。
1. ライブラリのインポートと初期化
import ee
import geemap
ee.Initialize()eeとgeemapをインポートします。eeは Earth Engine API、geemapは地図可視化用のライブラリです。ee.Initialize()で Earth Engine のセッションを初期化します。
2. データの取得と前処理
# Sentinel-2の表面反射率イメージの読み込み
img = ee.Image('COPERNICUS/S2_SR_HARMONIZED/20200417T012649_20200417T013323_T54TVM') \
.select('B.*')
# ESAのWorldCoverデータセットを使用
lc = ee.Image('ESA/WorldCover/v100/2020')
# 土地被覆クラスのリマッピング
class_values = [10, 20, 30, 40, 50, 60, 70, 80, 90, 95, 100]
remap_values = ee.List.sequence(0, 10)
label = 'lc'
lc = lc.remap(class_values, remap_values).rename(label).toByte()
# データセットの結合
sample_img = img.addBands(lc)- Sentinel-2の表面反射率イメージを特定の日付で読み込み、
B.*バンド(全てのバンド)を選択します。 - ESAのWorldCoverデータセットを読み込み、土地被覆クラスを0から始まる連続したシリーズにリマッピングします。
class_valuesは、WorldCoverデータセットに含まれる元の土地被覆クラスを定義しています(例えば、10は樹木、20は草地など)。remap_valuesは、これらのクラス値を0から始まる連続した整数にリマップするために使用される新しい値のシリーズです。lc.remap(class_values, remap_values).rename(label).toByte()は、元のクラス値を新しい連続した値にリマップし、それを新しいバンド名**'lc'**(土地被覆)でイメージに追加して、バイト型に変換しています。sample_img = img.addBands(lc)は、Sentinel-2のイメージ(img)にWorldCoverの土地被覆イメージ(lc)をバンドとして追加しています。これにより、反射率データと土地被覆データが組み合わされた新しいイメージが作成されます。
3. トレーニングデータの準備
# トレーニングデータのサンプリング
roi = ee.Geometry.Rectangle([140.625, 41.721, 140.868, 41.862])
sample = sample_img.stratifiedSample(
numPoints=5000,
classBand=label,
region=roi,
scale=10,
geometries=True
)
# データセットをトレーニングセットとバリデーションセットに分割
sample = sample.randomColumn()
training_sample = sample.filter('random <= 0.8')
validation_sample = sample.filter('random > 0.8')- 特定の地理的領域(
roi)内のデータから5000点のサンプルを抽出します。 - 抽出されたサンプルにランダムな列を追加し、80%をトレーニング用、20%をバリデーション用に分割します。
4. ランダムフォレスト分類器のトレーニング
# 分類器のトレーニング
trained_classifier = ee.Classifier.smileRandomForest(10).train(
features=training_sample,
classProperty=label,
inputProperties=img.bandNames()
)ee.Classifier.smileRandomForest(10)で決定木を10本に設定し、分類器をトレーニングサンプルからトレーニングします。
5. トレーニングとバリデーション精度の計算
# トレーニングサンプルの精度評価
train_accuracy = trained_classifier.confusionMatrix()
print('Training accuracy:', train_accuracy.accuracy().getInfo())
# バリデーションサンプルの分類と精度評価
validation_sample = validation_sample.classify(trained_classifier)
validation_accuracy = validation_sample.errorMatrix(label, 'classification')
print('Validation accuracy:', validation_accuracy.accuracy().getInfo())- トレーニングサンプルに基づく混同行列を作成し、その精度を計算します。
- バリデーションサンプルを分類し、その精度を計算します。
6. 分類されたイメージの生成と表示
# イメージの分類
classified_img = img.classify(trained_classifier)
# Add the layers to the map.
class_vis = {
'min': 0,
'max': 10,
'palette': [
'006400',
'ffbb22',
'ffff4c',
'f096ff',
'fa0000',
'b4b4b4',
'f0f0f0',
'0064c8',
'0096a0',
'00cf75',
'fae6a0',
],
}
# 地図の作成とレイヤーの追加
m = geemap.Map()
m.set_center(140.75, 41.79, 12)
m.addLayer(classified_img, class_vis, 'Classified')- トレーニングされた分類器を使用して、元のイメージを分類します。
- 分類されたイメージを地図に追加し、特定の色パレットで表示します。
'006400'(濃い緑色): 植生や森林。'ffbb22'(オレンジ色): 農地や草地。'ffff4c'(黄色): 裸地や砂地など、植生が少ない地域。'f096ff'(ピンク色): 農地、湿地や水域。'fa0000'(赤色): 都市化された地域や市街地。'b4b4b4'(灰色): 都市や建造物。'f0f0f0'(薄灰色): 雪や氷。'0064c8'(青色): 水域。'0096a0'(シアン): 河川や湖。'00cf75'(薄緑色): 植生や農地。'fae6a0'(ベージュ色): 砂漠や裸地。
- 最後にgeemapで地図を生成します。
Accuracyが低い場合は、まずは3.のnumPointsや4.のsmileRandomForest(10)の数値を調整してみてください。
最後に
GEEのAPIを利用すればあらかじめチューニングされた機械学習モデルを簡単に利用できます。
近年、リモートセンシングでは機械学習を利用したデータ分析が活発になってきており、その入門としてGEEを使用するのは敷居も低く大変便利です。
この機会にぜひ初めて見てはどうでしょうか。
Pythonを使った衛星データ解析の初心者向け技術書を販売中!
¥2,500 → ¥800 今なら約70%OFF!!
Google Earth Engineを使えば簡単に
自宅にいながら地球環境の変動を観察できます

