

マテリアルズインフォマティクス(MI)の理論を学び、いよいよ現実のデータで予測モデルを作ってみたいと思いませんか?
このハンズオンシリーズは、MIプロジェクトの現実的なワークフローをゼロから体験することを目指します。記念すべき第1回は、すべての分析の出発点となる「ベースラインモデル」の構築に挑戦します。モデルには、最もシンプルで解釈しやすい「線形回帰」を用い、鋼材の化学組成から機械的強度を予測するタスクに取り組みます。
しかし、今回のゴールは「精度の良いモデルを作ること」ではありません。むしろ、あえてシンプルなモデルを使うことで、現実の複雑なデータが引き起こす典型的な失敗例「過学習」に直面することが最大の目的です。
なぜモデルは失敗したのか?その結果をどう科学的に解釈し、次の一手につなげるか?――この「失敗の科学」こそ、データサイエンスにおける最も重要なスキルです。さあ、価値ある失敗を体験しにいきましょう。
Google Colaboratory
Python 3.11.13
matminer==0.9.3
scikit-learn==1.6.1
matplotlib==3.10.0




Gaussianを使った量子化学計算の初心者向け技術書を販売中
しばしば出くわすエラーへの対処法をはじめ
Gaussianと無料ソフトウェア Avogadro を組み合わせた物性解析手法が学べます!
この記事から学べること
- MIプロジェクトの「型」: データ準備からモデル構築、評価、そして失敗の分析まで、MIにおける機械学習プロジェクトの基本的なワークフローを一気通貫で習得できます。
- ベースラインの重要性: なぜ最初にシンプルなモデルを作るのか、その役割と価値を深く理解できます。これは、今後の高度なモデルの性能を評価するための客観的な「ものさし」となります。
- データ前処理の技術: 文字列データから数値の特徴量を生成する「特徴量エンジニアリング」や、モデルの性能を公正に評価するための「特徴量の標準化」といった、必須スキルを実践的に学べます。
- 「過学習」を科学的に診断する力: モデルの性能が訓練データとテストデータで大きく異なる「過学習」という現象を、評価指標とグラフを用いて客観的に診断し、その原因を論理的に考察する力を養います。
関連理論の解説
1. 今回の分析設計
このハンズオンでは、以下の設計で物性予測に挑戦します。
使用するデータセット: 材料科学ライブラリ
matminerに含まれるmatbench_steelsデータセットを使用します。これには、様々な鋼材の化学組成とその実測された降伏強度(yield strength)のデータが含まれています。使用する特徴量: 予測の「原因」となる特徴量として、化学組成式から抽出した14種類の元素の含有率(Fe, C, Mn, Si, Cr, Ni, Mo, V, N, Nb, Co, W, Al, Ti)のみを使用します。
モデルアーキテクチャ: 最もシンプルで基本的な機械学習モデルである「線形回帰(Linear Regression)」を
scikit-learnライブラリから使用します。これは、物性予測のベースライン(基準点)を確立するのに最適です。ワークフロー
# =================================================================== # 0. 環境構築:必要なライブラリのインストール # 1. 必要なライブラリのインポート # 2. データセットの読み込み & 3. 特徴量エンジニアリング # 4. 特徴量とターゲットの定義 # 5. データを訓練用とテスト用に分割 # 6. 特徴量の標準化 # 7. 線形回帰モデルの訓練 # 8. 予測の実行(Train & Test両方) # 9. 性能評価(Train & Test両方) # 10. 結果の可視化 # ===================================================================
2. 線形回帰モデルとは?
線形回帰は、機械学習の中で最も基本的で理解しやすいモデルの一つです。その根底には、「予測したい物性($y$)は、各元素($X_1, X_2, …$)の影響の単純な足し算で決まる」という非常にシンプルな仮定があります。
数式で表すと $y = aX_1 + bX_2 + …$ となり、モデルの学習とは、この係数( $a, b, …$ )をデータに最もよく合うように調整するプロセスを指します。このシンプルさゆえに、「どの元素がどれくらい物性に効くか」を係数の値から直感的に解釈しやすいのが最大の利点です。
3. 過学習(Overfitting)とは?
過学習は、機械学習モデルが直面する最も一般的な「病」です。これは、モデルが学習に使った訓練データ(教科書)に過剰に適合し、そのデータに特有のノイズや偶然のパターンまで「丸暗記」してしまった状態を指します。
- 症状: 訓練データ(教科書の問題)に対しては高得点を取るが、未知のテストデータ(本番の試験)に対しては全く対応できず、性能が著しく低下します。
- 診断: 訓練データとテストデータで、モデルの性能評価に大きな差が開いている場合、過学習を強く疑う必要があります。
実装方法
実行手順
- 以下のコードブロック全体をコピーします。
- Google Colaboratoryの新しいセルに貼り付けます。
- セルが選択されていることを確認し、
ShiftキーとEnterキーを同時に押してコードを実行します。
# ===================================================================
# 0. 環境構築:必要なライブラリのインストール
# ===================================================================
!pip install matminer==0.9.3 scikit-learn==1.6.1 matplotlib==3.10.0
# ===================================================================
# 1. 必要なライブラリのインポート
# ===================================================================
import matplotlib.pyplot as plt
import numpy as np
import re
from matminer.datasets import load_dataset
from sklearn.model_selection import train_test_split
from sklearn.linear_model import LinearRegression
from sklearn.metrics import mean_absolute_error, mean_squared_error, r2_score
from sklearn.preprocessing import StandardScaler
# ===================================================================
# 2. データセットの読み込み & 3. 特徴量エンジニアリング
# ===================================================================
print("ステップ2&3: データセットの読み込みと特徴量エンジニアリング...")
df = load_dataset("matbench_steels")
def extract_value(composition_string, element_name): pattern = r"{}(\d+\.?\d*)".format(element_name) match = re.search(pattern, str(composition_string)) if match: return float(match.group(1)) else: return 0.0
elements = [ "Fe", "C", "Mn", "Si", "Cr", "Ni", "Mo", "V", "N", "Nb", "Co", "W", "Al", "Ti",
]
for element in elements: df[element] = df["composition"].apply(lambda x: extract_value(x, element))
df_clean = df.drop(columns=["composition"])
print("完了しました。")
# ===================================================================
# 4. 特徴量とターゲットの定義
# ===================================================================
features = elements
target = "yield strength"
X = df_clean[features]
y = df_clean[target]
# ===================================================================
# 5. データを訓練用とテスト用に分割
# ===================================================================
print("\nステップ5: データを訓練データとテストデータに分割します...")
X_train, X_test, y_train, y_test = train_test_split( X, y, test_size=0.2, random_state=42
)
print("データの分割が完了しました。")
# ===================================================================
# 6. 特徴量の標準化
# ===================================================================
print("\nステップ6: 特徴量の標準化を行います...")
scaler = StandardScaler()
X_train_scaled = scaler.fit_transform(X_train)
X_test_scaled = scaler.transform(X_test)
print("標準化が完了しました。")
# ===================================================================
# 7. 線形回帰モデルの訓練
# ===================================================================
print("\nステップ7: 線形回帰モデルの学習を開始します...")
model = LinearRegression()
model.fit(X_train_scaled, y_train)
print("モデルの学習が完了しました。")
# ===================================================================
# 8. 予測の実行(Train & Test両方)
# ===================================================================
print("\nステップ8: 予測を実行します...")
y_train_pred = model.predict(X_train_scaled)
y_test_pred = model.predict(X_test_scaled)
print("予測が完了しました。")
# ===================================================================
# 9. 性能評価(Train & Test両方)
# ===================================================================
print("\nステップ9: モデルの性能を評価します...")
# 訓練データに対する性能評価
mae_train = mean_absolute_error(y_train, y_train_pred)
rmse_train = np.sqrt(mean_squared_error(y_train, y_train_pred))
r2_train = r2_score(y_train, y_train_pred)
# テストデータに対する性能評価
mae_test = mean_absolute_error(y_test, y_test_pred)
rmse_test = np.sqrt(mean_squared_error(y_test, y_test_pred))
r2_test = r2_score(y_test, y_test_pred)
print("\n" + "=" * 50)
print("【モデル性能評価の比較】")
print("\n--- 訓練データ (Train) ---")
print(f" 平均絶対誤差 (MAE) : {mae_train:.3f} MPa")
print(f" 二乗平均平方根誤差 (RMSE) : {rmse_train:.3f} MPa")
print(f" 決定係数 (R2 Score) : {r2_train:.3f}")
print("\n--- テストデータ (Test) ---")
print(f" 平均絶対誤差 (MAE) : {mae_test:.3f} MPa")
print(f" 二乗平均平方根誤差 (RMSE) : {rmse_test:.3f} MPa")
print(f" 決定係数 (R2 Score) : {r2_test:.3f}")
print("=" * 50 + "\n")
# ===================================================================
# 10. 結果の可視化
# ===================================================================
print("ステップ10: 予測結果をグラフで可視化します...")
plt.figure(figsize=(8, 8))
plt.style.use("seaborn-v0_8-whitegrid")
plt.scatter( y_train, y_train_pred, alpha=0.6, edgecolors="w", s=50, c="blue", label="Train",
)
plt.scatter( y_test, y_test_pred, alpha=0.6, edgecolors="w", s=50, c="red", label="Test",
)
max_val = max(y.max(), y_train_pred.max(), y_test_pred.max()) * 1.05
min_val = 0
plt.plot( [min_val, max_val], [min_val, max_val], "k--", lw=2, label="Ideal (y=x)",
)
plt.xlabel("Actual Yield Strength (MPa)", fontsize=14)
plt.ylabel("Predicted Yield Strength (MPa)", fontsize=14)
plt.title("Actual vs. Predicted Yield Strength (Linear Regression)", fontsize=16)
plt.legend(fontsize=12)
plt.xlim(min_val, max_val)
plt.ylim(min_val, max_val)
plt.grid(True)
plt.show()
print("処理はすべて完了しました。")実行結果と考察
衝撃的な結果:モデルの二つの顔
出力された性能評価は、このモデルが抱える深刻な問題を浮き彫りにします。
| データ種別 | MAE (MPa) | RMSE (MPa) | R²スコア |
|---|---|---|---|
| 訓練データ | 149.385 | 207.821 | 0.551 |
| テストデータ | 159.311 | 288.148 | -0.205 |
- 訓練データ(教科書)での性能: R²スコアが0.551。これは、モデルが学習に使ったデータの内容を、約55%は説明できていることを示します。完璧ではありませんが、データから何らかのパターンを学習しようとした努力の跡が見えます。
- テストデータ(本番試験)での性能: R²スコアが -0.205。これは衝撃的な結果です。マイナスの値は、モデルの予測が「常に全データの平均値を予測する」という最も単純な予測よりもさらに悪いことを意味します。つまり、このモデルは未知の問題に対しては全く役に立たない、むしろ有害でさえあるということです。
過学習の診断:グラフが語るモデルの「病状」
この「訓練データではそこそこ、テストデータでは最悪」という性能の大きなギャップこそが、「過学習」の典型的な症状です。モデルが訓練データに存在するパターンを「丸暗記」することに終始してしまい、物性の背後にある普遍的な法則を学ぶことができなかった結果、未知のデータに対する応用力(汎化性能)を完全に失ってしまったのです。
このモデルの「病状」は、下のグラフ(Parity Plot)からより深く読み解くことができます。
このグラフについて
このグラフは、モデルの予測精度を視覚的に評価するためのものです。
- 横軸は、実際の材料試験で測定された「実測値(Actual Yield Strength)」です。
- 縦軸は、私たちのモデルが算出した「予測値(Predicted Yield Strength)」です。
- グラフ中の **破線(Ideal y=x)**は、予測値と実測値が完全に一致する「理想的な状態」を示します。データ点がこの線に近ければ近いほど、モデルの精度が高いことを意味します。
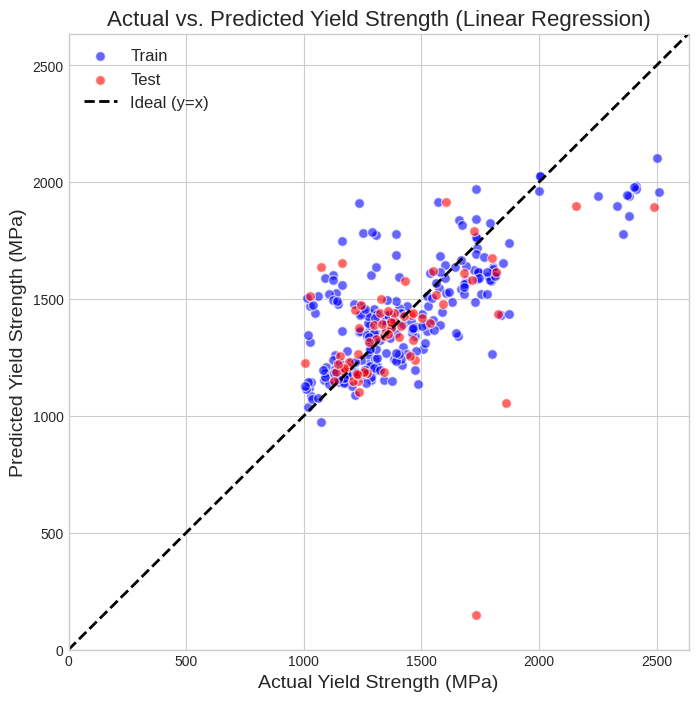
グラフから読み解く過学習の兆候
このグラフは、過学習の典型的な特徴を明確に示しています。
- 訓練データ(青い点)の傾向: ばらつきは大きいものの、全体としては理想線に沿うように、右肩上がりの弱い正の相関が見られます。これは、モデルが学習に使ったデータに対しては、ある程度の規則性を見つけ出そうと努力した結果です。
- テストデータ(赤い点)の傾向: 一方、赤い点は理想線とは全く無関係に、広範囲へばらばらに散らばっています。特に、実測値が高いにもかかわらず非常に低い値を予測してしまっている点(グラフ右下)など、モデルが未知のデータに対して「とんちんかんな予測」をしていることがわかります。
- 過学習の決定的証拠: 訓練データ(青)とテストデータ(赤)の分布の違いこそが、過学習の視覚的な証拠です。訓練データで学習したルールが、テストデータには通用していない(汎化していない)状態が一目瞭然です。これが、テストデータのR²スコアがマイナスになる直接的な原因です。
結論として、このモデルは「訓練データだけに存在する、その場限りのルールを学習してしまったがために、未知のデータに対しては全く役に立たなくなった」という、典型的な過学習の状態にあると診断できます。
コードの詳細解説
ソースコードの各ステップが、マテリアルズインフォマティクスのプロジェクトにおいてどのような意味を持つのか、その背景にある「なぜ?」という問いに答えながら、より深く掘り下げて解説します。
ステップ0 & 1: 環境構築とライブラリのインポート
これは、料理で言えば調理器具と食材を揃える、プロジェクトの最も基本的な準備段階です。
# ===================================================================
# 0. 環境構築:必要なライブラリのインストール
# ===================================================================
!pip install matminer==0.9.3 scikit-learn==1.6.1 matplotlib==3.10.0
# ===================================================================
# 1. 必要なライブラリのインポート
# ===================================================================
import matplotlib.pyplot as plt
import numpy as np
import re
from matminer.datasets import load_dataset
from sklearn.model_selection import train_test_split
from sklearn.linear_model import LinearRegression
from sklearn.metrics import mean_absolute_error, mean_squared_error, r2_score
from sklearn.preprocessing import StandardScaler!pip install ...: Google Colaboratoryのようなクラウド環境に、今回の分析で必要な専門ライブラリ群をインストールするコマンドです。これらはPythonに標準で備わっているわけではないため、最初に明示的に追加する必要があります。matminer: 材料科学(Materials Science)のデータ(Miner)を扱うための特化ライブラリ。今回は、世界中の研究者が利用するベンチマークデータセットを数行のコードで簡単に呼び出すために使用します。scikit-learn: 機械学習モデルの構築(LinearRegression)、データ分割(train_test_split)、性能評価(r2_scoreなど)、そして重要な前処理(StandardScaler)といった、機械学習プロジェクトの中心的な役割を担う総合ライブラリです。matplotlib: データをグラフとして可視化するためのライブラリです。数値だけでは分かりにくいモデルの性能を、直感的に理解するのに役立ちます。re: 「正規表現」という強力な文字列パターンマッチング機能を使うためのライブラリです。
import ...: インストールしたライブラリを、Pythonコードの中で実際に使えるようにする「おまじない」です。例えば**import numpy as npと書くことで、これ以降npという短い名前でnumpy**の全機能を呼び出せるようになります。
ステップ2 & 3: データセットの読み込みと特徴量エンジニアリング
AIが学習できる「きれいな数値データ」を準備する、データサイエンスにおいて最も創造的で重要な工程です。
# ===================================================================
# 2. データセットの読み込み & 3. 特徴量エンジニアリング
# ===================================================================
print("ステップ2&3: データセットの読み込みと特徴量エンジニアリング...")
df = load_dataset("matbench_steels")
def extract_value(composition_string, element_name): pattern = r"{}(\d+\.?\d*)".format(element_name) match = re.search(pattern, str(composition_string)) if match: return float(match.group(1)) else: return 0.0
elements = [ "Fe", "C", "Mn", "Si", "Cr", "Ni", "Mo", "V", "N", "Nb", "Co", "W", "Al", "Ti",
]
for element in elements: df[element] = df["composition"].apply(lambda x: extract_value(x, element))
df_clean = df.drop(columns=["composition"])
print("完了しました。")load_dataset("matbench_steels"): まず、matminerの機能を使って、分析対象となる鋼材のデータを読み込みます。この時点でのデータは、'Fe0.768C0.0009...'のような化学組成式(文字列)と、それに対応する降伏強度(数値)の組み合わせになっています。extract_value関数とループ処理: AIモデル、特に線形回帰のような数学的なモデルは、'Fe0.768...'という文字列を直接理解できません。モデルが学習できるのは数値だけです。そこで、この文字列から各元素(Fe, Cなど)に対応する含有率という「数値」を一つずつ取り出す必要があります。正規表現:
reライブラリの正規表現r'{}(\d+\.?\d*)'は、「指定した元素名の直後に続く、整数または小数の数値を抽出する」というルールを定義しています。applyメソッド: この自作した抽出ルールを、DataFrameの全てのデータ行のcomposition列に適用し、結果を新しい列(‘Fe’, ‘C’, ‘Mn’など)として追加していきます。この一連の処理が「特徴量エンジニアリング」であり、生のデータからモデルが学習に使える有益な特徴量(Feature)を設計・生成する、腕の見せ所となるプロセスです。
ステップ4 & 5: データ定義と分割
モデルに「何を」「何から」予測させるかを定義し、その性能を公正に評価するための準備をします。
# ===================================================================
# 4. 特徴量とターゲットの定義
# ===================================================================
features = elements
target = "yield strength"
X = df_clean[features]
y = df_clean[target]
# ===================================================================
# 5. データを訓練用とテスト用に分割
# ===================================================================
print("\nステップ5: データを訓練データとテストデータに分割します...")
X_train, X_test, y_train, y_test = train_test_split( X, y, test_size=0.2, random_state=42
)
print("データの分割が完了しました。")- 特徴量
Xとターゲットy:X(説明変数)には、予測の「原因」となるデータ、すなわち先ほど生成した14種類の元素含有率の列を全て格納します。y(目的変数)には、予測したい「結果」である降伏強度の列を格納します。
train_test_split: モデルの性能を公正に評価するための、機械学習における鉄則中の鉄則です。- なぜ分割が必要か?: もし手元にある全てのデータで学習とテストを行ってしまうと、モデルは答えを「丸暗記」しているだけかもしれません。それでは、未知の新しい材料に対してどれだけの実力があるのか全く分かりません。そこで、データを「訓練データ(教科書)」と「テストデータ(本番の試験)」に分割します。モデルは訓練データだけを見て学習し、一度も見たことのないテストデータでその性能を評価されます。これにより、モデルの真の実力である「汎化性能」を正しく測ることができます。
random_state=42: **scikit-learnはデータをランダムに分割しますが、このrandom_state**を特定の数値(慣例的に42がよく使われる)に固定することで、その「ランダムのパターン」を固定します。これを指定しないと、実行するたびに分割のされ方が変わり、結果が微妙に変動してしまいます。科学的な実験として、誰がいつ実行しても全く同じ結果が得られる「再現性」を担保するために、この設定は極めて重要です。
ステップ6: 特徴量の標準化
ここが今回の線形回帰モデル構築における、性能を左右する重要な一手です。
# ===================================================================
# 6. 特徴量の標準化
# ===================================================================
print("\nステップ6: 特徴量の標準化を行います...")
scaler = StandardScaler()
X_train_scaled = scaler.fit_transform(X_train)
X_test_scaled = scaler.transform(X_test)
print("標準化が完了しました。")- なぜ標準化が必要か?: 線形回帰は、各特徴量の「数値の大きさ(スケール)」に直接影響を受けます。例えば、含有率が**
~90%** のFeと~0.1%のCでは、数値の桁が大きく異なります。そのまま学習させると、モデルは数値の大きいFeの影響を過大評価し、微量でも物性に大きく寄与する元素の影響を過小評価してしまう可能性があります。そこで**StandardScaler**を使い、全元素を「平均0、標準偏差1」という同じ土俵に立たせる(標準化する)ことで、モデルが各元素の真の影響度を公平に比較・判断できるようにします。 fit_transformとtransformの厳密な使い分け: これは「データリーケージ(情報の漏洩)」という、モデル評価における重大なミスを防ぐための重要な作法です。scaler.fit_transform(X_train): ここでは2つの処理が同時に行われます。fitで訓練データの各特徴量の平均と標準偏差(=標準化するための「ものさし」)を学習します。そしてtransformで、その学習した「ものさし」を使って訓練データを実際に変換します。scaler.transform(X_test): テストデータは変換するだけです。ここで絶対にfitしてはいけません。なぜなら、テストデータは「未知のデータ」という設定だからです。テストデータの情報(平均や標準偏差)を使って「ものさし」を作ってしまうと、それは未来の試験問題をカンニングしているのと同じことになります。あくまで訓練データから作った「ものさし」を一方的にテストデータに適用することで、モデルの真の実力を公正に評価できるのです。
ステップ7, 8, 9, 10: モデルの訓練、予測、評価、可視化
これまでの準備を元に、いよいよモデルを動かし、その実力を多角的に検証します。
# ===================================================================
# 7. 線形回帰モデルの訓練
# ===================================================================
print("\nステップ7: 線形回帰モデルの学習を開始します...")
model = LinearRegression()
model.fit(X_train_scaled, y_train)
print("モデルの学習が完了しました。")
# ===================================================================
# 8. 予測の実行(Train & Test両方)
# ===================================================================
print("\nステップ8: 予測を実行します...")
y_train_pred = model.predict(X_train_scaled)
y_test_pred = model.predict(X_test_scaled)
print("予測が完了しました。")
# ===================================================================
# 9. 性能評価(Train & Test両方)
# ===================================================================
print("\nステップ9: モデルの性能を評価します...")
# 訓練データに対する性能評価
mae_train = mean_absolute_error(y_train, y_train_pred)
rmse_train = np.sqrt(mean_squared_error(y_train, y_train_pred))
r2_train = r2_score(y_train, y_train_pred)
# テストデータに対する性能評価
mae_test = mean_absolute_error(y_test, y_test_pred)
rmse_test = np.sqrt(mean_squared_error(y_test, y_test_pred))
r2_test = r2_score(y_test, y_test_pred)
print("\n" + "=" * 50)
print("【モデル性能評価の比較】")
print("\n--- 訓練データ (Train) ---")
print(f" 平均絶対誤差 (MAE) : {mae_train:.3f} MPa")
print(f" 二乗平均平方根誤差 (RMSE) : {rmse_train:.3f} MPa")
print(f" 決定係数 (R2 Score) : {r2_train:.3f}")
print("\n--- テストデータ (Test) ---")
print(f" 平均絶対誤差 (MAE) : {mae_test:.3f} MPa")
print(f" 二乗平均平方根誤差 (RMSE) : {rmse_test:.3f} MPa")
print(f" 決定係数 (R2 Score) : {r2_test:.3f}")
print("=" * 50 + "\n")
# ===================================================================
# 10. 結果の可視化
# ===================================================================
print("ステップ10: 予測結果をグラフで可視化します...")
plt.figure(figsize=(8, 8))
plt.style.use("seaborn-v0_8-whitegrid")
plt.scatter( y_train, y_train_pred, alpha=0.6, edgecolors="w", s=50, c="blue", label="Train",
)
plt.scatter( y_test, y_test_pred, alpha=0.6, edgecolors="w", s=50, c="red", label="Test",
)
max_val = max(y.max(), y_train_pred.max(), y_test_pred.max()) * 1.05
min_val = 0
plt.plot( [min_val, max_val], [min_val, max_val], "k--", lw=2, label="Ideal (y=x)",
)
plt.xlabel("Actual Yield Strength (MPa)", fontsize=14)
plt.ylabel("Predicted Yield Strength (MPa)", fontsize=14)
plt.title("Actual vs. Predicted Yield Strength (Linear Regression)", fontsize=16)
plt.legend(fontsize=12)
plt.xlim(min_val, max_val)
plt.ylim(min_val, max_val)
plt.grid(True)
plt.show()
print("処理はすべて完了しました。")model.fit(X_train_scaled, y_train): これが「学習」を実行するコマンドです。標準化された訓練データを使って、線形回帰モデルに最適な係数(各元素の重み)を、最小二乗法という数学的な手法で計算させます。model.predict(): 学習が完了したモデルは、内部にy = a*X_Fe + b*X_C + ...という方程式を持っています。このコマンドは、新しいデータ(X_train_scaledやX_test_scaled)をこの方程式に代入し、予測値**y**を計算するプロセスです。- 性能評価: 3つの評価指標(MAE, RMSE, R²)を計算し、モデルの性能を定量化します。
- MAE/RMSE: 予測が平均してどれくらい外れているかを示します。単位が目的変数と同じ(この場合はMPa)なので直感的に分かりやすいです。
- R²スコア(決定係数): モデルがデータのばらつきをどれだけうまく説明できているかを示す、0から1の範囲の指標(今回はマイナスですが)。1に近いほど良いモデルです。特に訓練データとテストデータのR²スコアを比較することで、過学習の有無を客観的に診断します。
- Parity Plotによる可視化: 数値だけでは伝わりにくいモデルの挙動を、グラフで直感的に理解します。このグラフの目的は、予測がどれだけ「理想」に近いかを確認することです。点が理想線(y=x)から大きく外れていればいるほど、予測精度が悪いことを意味します。訓練データ(青)とテストデータ(赤)のプロットの分布の違いを見ることで、過学習の深刻さを視覚的に捉えることができます。
最後に
今回のハンズオンでは、線形回帰というシンプルなモデルが、複雑な現実のデータに対してはいとも簡単に過学習に陥ることを体験しました。R²スコアがマイナスになるという結果は、一見すると完全な失敗です。
しかし、データサイエンスの世界では、これは「このシンプルなアプローチでは、この問題を解くには力不足である」ということを明確に証明できた、極めて価値のある知見なのです。
この「失敗したベースラインモデル」の存在が、次の一手を考えるための強力な動機となります。なぜなら、これから導入するより高度なモデルの性能が「本当に良いのか」を判断するための、客観的な比較対象(ものさし)が手に入ったからです。
次回は、この過学習問題を克服するため、より複雑な非線形な関係性を捉え、高い汎化性能を持つモデル「CatBoost」に挑戦します。線形モデルでは手も足も出なかったこの課題を、いかにして攻略するのか、ぜひご期待ください。
Gaussianを使った量子化学計算の初心者向け技術書を販売中
しばしば出くわすエラーへの対処法をはじめ
Gaussianと無料ソフトウェア Avogadro を組み合わせた物性解析手法が学べます!

