

これまでの9回にわたるシリーズで、私たちはMIの核心的なワークフローを一気通貫で学んできました。その結果、私たちの手元には、既存の材料を超える性能を持つ候補を提案できる、強力な「探索エンジン」が完成しました。
そこで入門編の最終回となる今回は、このMIの成果を、より多くの人々に「届ける」ための架け橋を架けます。テーマは「MIを届けよう!Streamlitで対話的なWebアプリ開発」です。Pythonの知識がなくても直感的に操作できるWebアプリケーションを驚くほど簡単に構築できるフレームワークStreamlitを使い、私たちが育て上げた予測モデルを、Google Colaboratory上から直接起動できる、より実践的で高機能なWebアプリケーションとして、誰でも使えるツールへと昇華させます。
Google Colaboratory
Python 3.11.13
matminer==0.9.3
pandas==2.2.2
scikit-learn==1.6.1
matplotlib==3.10.0
catboost==1.2.8
streamlit==1.46.1
pyngrok==7.2.12
plotly==5.24.1




Gaussianを使った量子化学計算の初心者向け技術書を販売中
しばしば出くわすエラーへの対処法をはじめ
Gaussianと無料ソフトウェア Avogadro を組み合わせた物性解析手法が学べます!
この記事から学べること
- MI成果の実用化: 学習済みの予測モデルを、専門家でないユーザーでも直感的に使える対話型Webアプリへと昇華させる、MIプロジェクトの最終的な価値提供プロセスを体験します。
- ColabからのWebアプリ公開: Google Colabと
pyngrokを使い、サーバー契約なしで、開発したStreamlitアプリを外部に公開して共有する具体的な技術を習得します。 - 洗練されたUI/UXの構築:
st.number_inputによる高精度入力st.tabsやst.expanderを使った情報整理、st.metricによる文脈付きのフィードバックなど、ユーザーの意思決定を支援する実用的なUIを構築する方法を学びます。 - インタラクティブな可視化:
Plotlyを用いて、ユーザーが探索的にデータを分析できる、リッチなホバー表示やズーム機能を持つ動的なグラフをアプリに組み込む方法を学びます。
関連理論の解説
この高機能なWebアプリケーションは、2つの重要な技術要素の組み合わせによって実現されています。それぞれの役割を詳しく見ていきましょう。
1. Streamlit:データサイエンスの成果を届けるフレームワーク
MIプロジェクトで構築した予測モデルは、それ単体では専門家しか扱えない「宝の持ち腐れ」です。Streamlitは、このAIの頭脳を、誰もが直感的に操作できるWebインターフェースに組み込むためのフレームワークです。
- なぜStreamlitか?: 通常、Webアプリ開発にはHTMLやJavaScriptといった専門知識が必要ですが、Streamlitは使い慣れたPythonだけで完結します。
st.titleでタイトルを、st.number_inputで数値入力フィールドを、st.buttonでボタンを設置するといった具合に、まるでドキュメントを書くようにUIを構築できます。 - MIとの親和性: pandasのDataFrameを美しいテーブルで表示したり、Plotlyの対話的なグラフを一行で埋め込んだりと、データサイエンスの成果物を可視化・共有する機能が豊富に揃っています。これにより、材料科学者が「この組成を試したら強度はどうなる?」という仮想実験をブラウザ上で繰り返せる、実用的なツールを迅速に開発できるのです。
2. pyngrok:閉じた環境に「窓」を開けるトンネル
Google Colabは、無料で高性能な計算環境を提供してくれますが、その実体はクラウド上にある一時的なプライベートサーバーです。そのため、Colab上でStreamlitアプリを起動しても、そのサーバーには自分のPCや他の人のスマホから直接アクセスすることはできません。
- 課題: 閉じたColab環境で動いているアプリを、どうやって外部のブラウザから利用可能にするか?
- 解決策: この課題を解決するのが
pyngrokです。このライブラリは、あなたのColab環境(内部)とインターネット(外部)との間に、安全な トンネル を掘ります。そして、そのトンネルの入り口となる一時的な公開URL(例:https://xxxx-xxxx.ngrok.io)を生成します。ユーザーはこのURLにアクセスするだけで、トンネルを通ってColab上のアプリを操作できるのです。これにより、サーバー契約なしで、開発したプロトタイプを世界中の共同研究者や上司と簡単に共有できます。
実装方法
実行手順
- ngrokの準備
- ngrokの公式サイトにアクセスし、無料アカウントを登録またはログインします。
- ログイン後、左側のメニューから「Your Authtoken」ページを開き、表示されている認証トークンをコピーします。

- コードの実行
- 以下のコードブロック全体をコピーします。
- Google Colaboratoryの新しいセルに貼り付けます。
- コード内の
!ngrok config add-authtoken YOUR_AUTHTOKEN_HEREという行を探し、YOUR_AUTHTOKEN_HEREの部分を、ステップ1でコピーした ご自身の認証トークン に置き換え ます。 - セルが選択されていることを確認し、
ShiftキーとEnterキーを同時に押してコードを実行します。
- アプリへのアクセス
- セルの実行が完了すると、出力の最後に
🎉 アプリが起動しました!こちらのURLからアクセスしてください: ...というメッセージとURLが表示されます。このURLをクリックしてください。 - 遷移先の画面で”Visit Site”ボタンを押してください。
- セルの実行が完了すると、出力の最後に
Google Colab用 実行コード
# ===================================================================
# ステップ1: 必要なライブラリのインストール
# ===================================================================
!pip install matminer==0.9.3 scikit-learn==1.6.1 pandas==2.2.2
!pip install matplotlib==3.10.0 catboost==1.2.8
!pip install streamlit==1.46.1 pyngrok==7.2.12 plotly==5.24.1
# ===================================================================
# ステップ2: Streamlitアプリケーションのコードをapp.pyとして保存
# ===================================================================
app_code = """
import streamlit as st
import pandas as pd
import plotly.express as px
from matminer.datasets import load_dataset
from catboost import CatBoostRegressor
# --- 1. 初期設定とモデル学習 ---
@st.cache_resource
def setup_app(): df = load_dataset("steel_strength") df_clean = df.dropna().reset_index(drop=True) features = [ col for col in df_clean.columns if col not in [ "composition", "formula", "yield strength", "tensile strength", "elongation", ] ] targets = ["yield strength", "tensile strength"] X = df_clean[features] y = df_clean[targets] model = CatBoostRegressor(random_seed=42, verbose=0, loss_function="MultiRMSE") model.fit(X, y) y_sum = y.sum(axis=1) champion_index = y_sum.idxmax() champion_composition = X.loc[champion_index] champion_properties = y.loc[champion_index] return { "model": model, "X_train": X, "y_train": y, "features": features, "champion_comp": champion_composition, "champion_props": champion_properties, }
config = setup_app()
model, X_train, y_train, features = ( config["model"], config["X_train"], config["y_train"], config["features"],
)
champion_comp, champion_props = config["champion_comp"], config["champion_props"]
# --- 2. 状態管理 (Session State) の初期化 ---
if "input_composition" not in st.session_state: st.session_state.input_composition = champion_comp.to_dict()
# --- 3. UI定義 ---
st.set_page_config(page_title="鋼材強度予測シミュレーター", layout="wide")
st.title("👩🔬 鋼材強度予測シミュレーター (高精度入力対応版)")
# --- サイドバー (入力部) ---
with st.sidebar: st.header("🔬 化学組成 (%)") st.markdown("数値を直接入力するか、`▲ ▼`ボタンで調整してください。") if st.button("チャンピオン組成にリセット", use_container_width=True): st.session_state.input_composition = champion_comp.to_dict() st.rerun() major_elements = ["c", "mn", "si", "ni", "cr", "mo", "co"] minor_elements = [el for el in features if el not in major_elements] current_inputs = st.session_state.input_composition.copy() st.markdown("**主要元素**") for el in major_elements: val = champion_comp[el] # 【改善点】st.slider から st.number_input に変更 current_inputs[el] = st.number_input( label=el.upper(), min_value=float(val * 0.5), max_value=float(val * 1.5), value=current_inputs[el], step=0.001, # 細かいステップ調整を可能に format="%.4f", # 表示フォーマット key=f"input_{el}", ) with st.expander("微量元素を表示"): for el in minor_elements: val = champion_comp[el] if val == 0: st.text_input(el.upper(), "0.0 (固定)", disabled=True) current_inputs[el] = 0.0 else: # 【改善点】st.slider から st.number_input に変更 current_inputs[el] = st.number_input( label=el.upper(), min_value=float(val * 0.5), max_value=float(val * 1.5), value=current_inputs[el], step=0.001, format="%.4f", key=f"input_{el}", ) st.session_state.input_composition = current_inputs
# --- メイン画面 (出力部) ---
input_df = pd.DataFrame([st.session_state.input_composition])
predicted_properties = model.predict(input_df)
pred_yield, pred_tensile = predicted_properties[0, 0], predicted_properties[0, 1]
st.header("📊 予測結果サマリー")
col1, col2 = st.columns(2)
with col1: st.metric( label="予測 降伏強度", value=f"{pred_yield:.2f} MPa", delta=f"{pred_yield - champion_props['yield strength']:.2f} MPa (vs Champion)", )
with col2: st.metric( label="予測 引張強さ", value=f"{pred_tensile:.2f} MPa", delta=f"{pred_tensile - champion_props['tensile strength']:.2f} MPa (vs Champion)", )
tab1, tab2, tab3 = st.tabs(["📈 物性マップ", "📝 詳細な組成", "🏆 チャンピオンデータ"])
with tab1: st.subheader("物性マップ上の予測位置") plot_df = y_train.copy() plot_df["label"] = "学習データ" user_point = pd.DataFrame( { "yield strength": [pred_yield], "tensile strength": [pred_tensile], "label": ["あなたのカスタム組成"], } ) fig = px.scatter( plot_df, x="tensile strength", y="yield strength", color="label", color_discrete_map={ "学習データ": "rgba(128, 128, 128, 0.4)", "あなたのカスタム組成": "magenta", }, hover_data={ "yield strength": ":.2f", "tensile strength": ":.2f", "label": False, }, title="引張強さ vs 降伏強度", ) fig.add_trace( px.scatter( user_point, x="tensile strength", y="yield strength", color="label", color_discrete_map={"あなたのカスタム組成": "magenta"}, ).data[0] ) fig.update_traces( marker=dict(size=12, line=dict(width=2, color="DarkSlateGrey")), selector=dict(mode="markers", name="あなたのカスタム組成"), ) fig.update_layout(legend_title_text="凡例") st.plotly_chart(fig, use_container_width=True)
with tab2: st.subheader("現在入力されている組成") st.dataframe(input_df.style.format("{:.4f}"))
with tab3: st.subheader("基準となるチャンピオンデータ") st.markdown( "このデータセットの中で、降伏強度と引張強さの合計値が最も高い材料のデータです。" ) st.json(champion_comp.to_dict()) st.metric("降伏強度", f"{champion_props['yield strength']:.2f} MPa") st.metric("引張強さ", f"{champion_props['tensile strength']:.2f} MPa")
"""
# 上記のコードをapp.pyファイルとして書き込む
with open("app.py", "w") as f: f.write(app_code)
# ===================================================================
# ステップ3: ngrokを設定し、Streamlitを起動
# ===================================================================
from pyngrok import ngrok
# ここに、ngrokのウェブサイトからコピーしたご自身の認証トークンを貼り付けてください
!ngrok config add-authtoken YOUR_AUTHTOKEN_HERE
# Streamlitをバックグラウンドで実行
!streamlit run app.py &>/dev/null&
# ngrokでトンネルを作成し、公開URLを取得
public_url = ngrok.connect(8501)
print(f"🎉 アプリが起動しました!こちらのURLからアクセスしてください: {public_url}")アプリケーションの使い方
生成されたURLにアクセスすると、下の画像のような「鋼材強度予測シミュレーター」が表示されます。このツールの各機能の使い方を解説します。
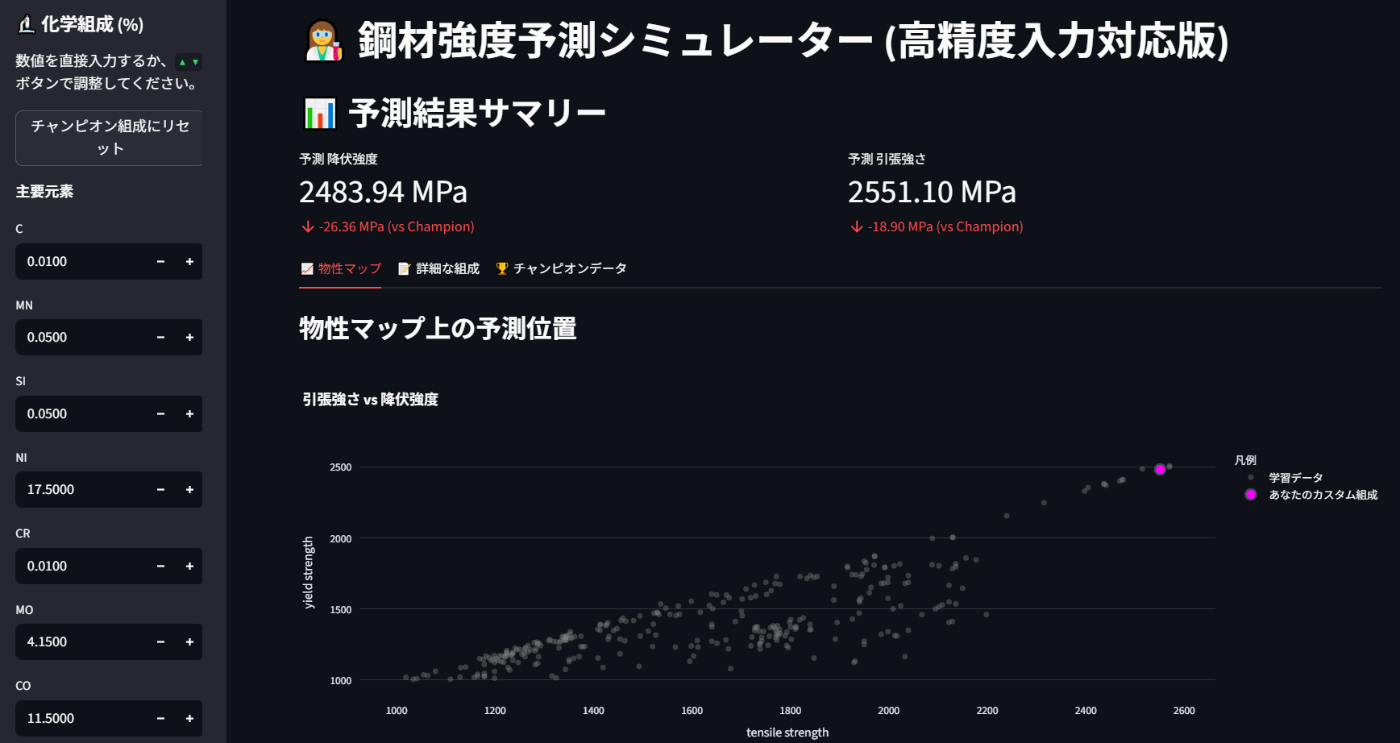
1. 化学組成の入力(画面左:サイドバー)
アプリケーションの心臓部です。ここで仮想的な材料の化学組成を定義します。
- 数値入力: サイドバーには各元素の入力フィールドが並んでいます。スライダー方式から、数値を直接キーボードで入力したり、フィールド横の「+」「-」ボタンで微調整したりできます。これにより、より現実に即した精密な組成の検討が可能です。
- リセット機能: 「チャンピオン組成にリセット」ボタンを押すと、いつでも基準となる最も優れた材料の組成に戻すことができます。様々な組成を試した後、出発点に簡単に戻れるため、試行錯誤が格段にしやすくなります。
- 主要元素と微量元素: 使用頻度の高い「主要元素」は常に表示し、影響度の低い「微量元素」は(折りたたみメニュー)に格納しました。これにより、インターフェースがすっきりし、重要な元素の調整に集中できます。
2. 予測結果の確認(画面中央:メインパネル)
サイドバーで組成を調整すると、その結果がリアルタイムでメインパネルに反映されます。
- 結果サマリー: 「予測 降伏強度」と「予測 引張強さ」が大きな文字で表示されます。さらに、その下にはチャンピオンデータと比較してどれだけ数値が上下したかが自動で計算され(例:
26.35 MPa (vs Champion))、行った組成変更が良い影響を与えたかを直感的に判断できます。 - タブによる情報整理: 結果は「物性マップ」「詳細な組成」「チャンピオンデータ」の3つのタブに整理されています。これにより、膨大な情報をすっきりと表示し、ユーザーは見たい情報にすぐにアクセスできます。
3. 物性マップでの視覚的確認(📈 物性マップ タブ)
現在シミュレーションしている材料が、全体のどのあたりに位置するのかを視覚的に把握できます。
- 灰色の点群: 学習に用いた全材料の物性分布です。
- マゼンタの星印: あなたが今、サイドバーで作成したカスタム組成の予測物性値の位置を示します。この星印を、目標とする特性領域(例えば、グラフの右上)に近づけるように組成を調整するのが、このツールの基本的な使い方です。
- インタラクティブな操作: グラフは
Plotlyで描画されているため、各データポイントにマウスカーソルを合わせると、その点の詳細な物性値がポップアップで表示されます。
4. 詳細な数値の確認(📝 詳細な組成 タブ)
現在入力されている組成の正確な数値を一覧で確認できます。レポート作成などのために、具体的な数値をコピーする際に便利です。

5. 基準データの確認(🏆 チャンピオンデータ タブ)
比較の基準となる「チャンピオンデータ」の詳細を確認できます。どのような組成が優れた特性を持つのかを理解するためのベースラインとして役立ちます。

コードの詳細解説
この高機能なアプリケーションを実現しているコードの核心部分を、さらに詳しく解説します。
1. 状態管理 (st.session_state)
# --- 2. 状態管理 (Session State) の初期化 ---
if 'input_composition' not in st.session_state: st.session_state.input_composition = champion_comp.to_dict()
# ... (サイドバー内) ...
# 状態を読み出し、ウィジェットのデフォルト値として使用
value=current_inputs[el],
# ... (サイドバーの最後) ...
# ユーザーが変更した値を状態に書き戻す
st.session_state.input_composition = current_inputsStreamlitアプリは、ウィジェットを操作するたびにスクリプト全体が再実行されるのが基本です。これでは入力した値が毎回リセットされてしまいます。そこで st.session_state の出番です。
- 初期化:
if 'input_composition' not in st.session_state:というコードで、アプリの初回起動時のみ、st.session_stateにinput_compositionというキーでチャンピオン組成の辞書を保存します。 - 読み書き: ユーザーが数値を入力するたびに、スクリプトは再実行されますが、
st.session_stateに保存された値は保持されます。コードは常にこのsession_stateから現在の値を読み込み、ウィジェットの値を更新し、そしてユーザーの最新の入力をまたsession_stateに書き戻します。これにより、アプリはユーザーの入力値を「記憶」し続けることができるのです。 - リセットボタン: このボタンが押されると、
session_stateの中身をチャンピオン組成で上書きし、st.rerun()で画面を強制的に再描画することで、リセット機能を実現しています。
2. 高精度な入力 (st.number_input)
current_inputs[el] = st.number_input( label=el.upper(), min_value=float(val * 0.5), # 最小値 max_value=float(val * 1.5), # 最大値 value=current_inputs[el], # 現在の値 (session_stateから) step=0.001, # 調整の刻み幅 format="%.4f", # 表示形式
)スライダー(st.slider)は直感的ですが、精密な数値入力には不向きです。そこで st.number_input を採用しました。
- 直接入力 : ユーザーはキーボードで
0.0123のような具体的な値を直接入力できます。 step引数:+ボタンを押した際の増減量を細かく設定できます。ここでは0.001とすることで、微量な調整を可能にしています。
3. 状況がわかる評価指標 (st.metric)
st.metric( label="予測 降伏強度", value=f"{pred_yield:.2f} MPa", delta=f"{pred_yield - champion_props['yield strength']:.2f} MPa (vs Champion)"
)数値をただ表示するだけでなく、文脈を加えて示すのが**st.metric**です。
value: メインで表示する大きな数値(予測値)です。delta:valueの下に小さく表示される比較値です。ここでは、予測値とチャンピオンの物性値との差分(delta)を計算して渡しています。これにより、ユーザーは組成変更がポジティブな影響を与えたか、ネガティブだったかを一目で把握できます。
4. 対話的なグラフ描画 (Plotly Express)
# Plotly Expressで散布図を作成
fig = px.scatter( plot_df, x='tensile strength', y='yield strength', color='label', # ... その他の設定 ...
)
# 別のデータ(ユーザーの点)をトレースとして追加
fig.add_trace(...)
# 特定のトレースの見た目を更新
fig.update_traces(...)
# StreamlitでPlotlyのグラフを表示
st.plotly_chart(fig, use_container_width=True)静的なグラフを描画するMatplotlibではなく、Webと親和性の高いインタラクティブなグラフライブラリ Plotly を使用しました。
- 表現力:
px.scatterで簡単に美しいグラフが作成できます。色やサイズ、ホバー時に表示する情報などを細かく設定可能です。 - 対話性: ユーザーはグラフ上の点にカーソルを合わせるだけで、その点の詳細な数値情報を確認できます。ズームやパン(グラフの移動)も自由自在です。
st.plotly_chart: 作成したPlotlyのグラフオブジェクト(fig)を、このコマンド一つでStreamlitアプリ内に埋め込むことができます。use_container_width=Trueは、グラフを画面幅いっぱいに広げる便利なオプションです。
最後に
今回は、MIプロジェクトの成果を、専門家でないユーザーにも届けるための最終ステップとして、高機能な対話型Webアプリケーションの開発に挑戦しました。状態管理や高度なUIコンポーネントを導入することで、私たちが育て上げた予測エンジンが、より実用的なツールへと生まれ変わるプロセスを体験しました。
全10回にわたったこの入門シリーズでは、材料データの基本的な取り扱いから始まり、予測モデルの構築と解釈、HTVSやベイズ最適化による未知材料の探索、そして最終的には、その成果を届けるためのアプリケーション開発まで、マテリアルズインフォマティクスの主要なワークフローを一気通貫で旅してきました。
このシリーズが、皆さまにとってMIの世界への扉を開き、データ駆動型のアプローチをご自身の材料開発や研究に取り入れるための一助となれば、これに勝る喜びはありません。データに基づいた材料探索の旅は、まだ始まったばかりです。ぜひ、ここで学んだ技術を応用し、新たな発見へと繋げてください。
Gaussianを使った量子化学計算の初心者向け技術書を販売中
しばしば出くわすエラーへの対処法をはじめ
Gaussianと無料ソフトウェア Avogadro を組み合わせた物性解析手法が学べます!

