

第2回では、高性能なCatBoostモデルを構築し、鋼材の降伏強度を高い精度で予測しました。しかし、そのモデルは「なぜ」その予測をしたのかが分からない「ブラックボックス」でした。
本第3回では、このブラックボックスモデルに光を当てる「説明可能なAI(XAI)」の代表的な手法であるSHAP(SHapley Additive exPlanations)を導入します。SHAPを用いることで、どの元素が、なぜ、どれくらい強度に影響を与えたのかを個々の予測レベルまで掘り下げて可視化し、AIの予測結果に材料科学的な洞察と信頼性を与えるプロセスを体験します。
Google Colaboratory
Python 3.11.13
matminer==0.9.3
scikit-learn==1.6.1
pandas==2.2.2
matplotlib==3.10.0
catboost==1.2.8
shap==0.48.0




Gaussianを使った量子化学計算の初心者向け技術書を販売中
しばしば出くわすエラーへの対処法をはじめ
Gaussianと無料ソフトウェア Avogadro を組み合わせた物性解析手法が学べます!
この記事から学べること
説明可能なAI(XAI)の概念
なぜ高性能なモデルの「解釈」が重要なのか、その基本的な考え方を理解できます。
SHAPの理論と実践
SHAPがどのようにして各特徴量(元素)の貢献度を算出するのか、その仕組みの概要とPythonでの実装方法をマスターできます。
定性的な可視化と定量的な評価
Forceプロットによる視覚的な貢献度の理解に加え、実際のSHAP値を表で確認し、定量的に評価する技術を習得できます。
個別の予測理由の画像化
特定の鋼材サンプルに対する予測の根拠を、レポートや論文に活用しやすい静的な画像ファイルとして出力できます。
関連理論の解説
1. 説明可能なAI(XAI)とは?
CatBoostのような高性能モデルは「ブラックボックス」と呼ばれます。これは、モデルが高精度な予測を行う一方で、その予測に至った理由やプロセスを人間が直感的に理解しにくいためです。特に材料科学などの分野では、「なぜその予測になるのか」という因果関係の理解が不可欠です。
XAI(Explainable AI)は、このブラックボックスの内部を可視化・解釈し、AIの判断根拠を人間が理解可能な形で提示する技術分野です。XAIを用いることで、モデルへの信頼性を高め、新たな科学的知見を得るきっかけを掴めます。
2. SHAP (SHapley Additive exPlanations) とは?
SHAPはXAIを実現する代表的手法の一つで、協力ゲーム理論の「シャープレイ値」を応用しています。機械学習における各特徴量(元素)をゲームのプレイヤー、予測値を報酬と見なし、ある予測値が全特徴量の平均的な予測値からどれだけズレているかを計算します。
そのズレを各特徴量の貢献度に公平に分配し、特定の予測に対してどの元素がどれくらい予測値を押し上げたり押し下げたりしたかを、すべての特徴量を考慮した上で定量的に示します。
実装方法
ワークフロー
# ===================================================================
# 0. 環境構築:必要なライブラリのインストール
# 1. 必要なライブラリのインポート
# 2. データセットの読み込み & 3. 特徴量エンジニアリング
# 4. 特徴量とターゲットの定義
# 5. データを訓練用とテスト用に分割
# 6. CatBoostモデルの訓練
# 7. SHAPを用いたモデル解釈
# 8. SHAPプロットによる可視化と定量的評価
# ===================================================================実行手順
- 以下のコードブロック全体をコピーします。
- Google Colaboratoryの新しいセルに貼り付けます。
- セルが選択されていることを確認し、
ShiftキーとEnterキーを同時に押してコードを実行します。
# ===================================================================
# 0. 環境構築:必要なライブラリのインストール
# ===================================================================
!pip install matminer==0.9.3 pandas==2.2.2 scikit-learn==1.6.1
!pip install matplotlib==3.10.0 catboost==1.2.8 shap==0.48.0
# ===================================================================
# 1. 必要なライブラリのインポート
# ===================================================================
import pandas as pd
import matplotlib.pyplot as plt
import re
from matminer.datasets import load_dataset
from sklearn.model_selection import train_test_split
from catboost import CatBoostRegressor
import shap
from IPython.display import display, Image
# ===================================================================
# 2. データセットの読み込み & 3. 特徴量エンジニアリング
# ===================================================================
print("ステップ2&3: データセットの読み込みと特徴量エンジニアリング...")
df = load_dataset("matbench_steels")
def extract_value(composition_string, element_name): pattern = r"{}(\d+\.?\d*)".format(element_name) match = re.search(pattern, str(composition_string)) if match: return float(match.group(1)) else: return 0.0
elements = [ "Fe", "C", "Mn", "Si", "Cr", "Ni", "Mo", "V", "N", "Nb", "Co", "W", "Al", "Ti",
]
for element in elements: df[element] = df["composition"].apply(lambda x: extract_value(x, element))
df_clean = df.drop(columns=["composition"])
print("完了しました。")
# ===================================================================
# 4. 特徴量とターゲットの定義
# ===================================================================
features = elements
target = "yield strength"
X = df_clean[features]
y = df_clean[target]
# ===================================================================
# 5. データを訓練用とテスト用に分割
# ===================================================================
print("\nステップ5: データを訓練データとテストデータに分割します...")
X_train, X_test, y_train, y_test = train_test_split( X, y, test_size=0.2, random_state=42
)
print("データの分割が完了しました。")
# ===================================================================
# 6. CatBoostモデルの訓練
# ===================================================================
print("\nステップ6: CatBoost回帰モデルの学習を開始します...")
model = CatBoostRegressor(random_seed=42, verbose=0)
model.fit(X_train, y_train)
print("モデルの学習が完了しました。")
# ===================================================================
# 7. SHAPを用いたモデル解釈
# ===================================================================
print("\nステップ7: SHAPを用いてモデルの解釈を行います...")
explainer = shap.TreeExplainer(model)
shap_values = explainer.shap_values(X_test)
print("SHAP値の計算が完了しました。")
# ===================================================================
# 8. SHAPプロットによる可視化と定量的評価
# ===================================================================
print("\nステップ8: SHAPの可視化と定量的評価を行います...")
# (1) グローバルな特徴量重要度 (Summary Plot)
print("\n--- (1) グローバルな特徴量重要度 (Summary Plot) ---")
shap.summary_plot(shap_values, X_test, plot_type="bar")
# (2) 各特徴量の影響を詳細に可視化 (Beeswarm Plot)
print("\n--- (2) 各特徴量の影響の詳細 (Beeswarm Plot) ---")
shap.summary_plot(shap_values, X_test)
# (3) 個別の予測に対する貢献度を画像として保存 (Force Plot)
print("\n--- (3) 個別の予測に対する貢献度 (Force Plot) ---")
force_plot = shap.force_plot( explainer.expected_value, shap_values[0, :], X_test.iloc[0, :], matplotlib=True, show=False,
)
plt.savefig("shap_force_plot_sample.png", format="png", bbox_inches="tight")
plt.close()
print("Forceプロットを 'shap_force_plot_sample.png' として保存しました。")
display(Image("shap_force_plot_sample.png"))
# (4) 個別の予測貢献度を数値で確認
print("\n--- (4) 個別の予測貢献度を数値(SHAP値)で確認 ---")
shap_df = pd.DataFrame({"Feature_Value": X_test.iloc[0], "SHAP_Value": shap_values[0]})
shap_df["SHAP_abs"] = shap_df["SHAP_Value"].abs()
shap_df_sorted = shap_df.sort_values(by="SHAP_abs", ascending=False).drop( columns=["SHAP_abs"]
)
base_value = explainer.expected_value
predicted_value = model.predict(X_test.iloc[[0]])[0]
shap_sum = shap_df["SHAP_Value"].sum()
print(f"ベース値 (平均予測値): {base_value:.2f}")
print(f"このサンプルの予測値: {predicted_value:.2f}")
print(f"SHAP値の合計: {shap_sum:.2f}")
print(f"予測値 - ベース値: {(predicted_value - base_value):.2f}")
print("\n貢献度が大きい順に並べた特徴量とSHAP値:")
display(shap_df_sorted)
print("\n処理はすべて完了しました。")実行結果と考察
1. モデルはどの元素を重要視しているのか? (Global Importance)
summary_plot の棒グラフは、モデルが鋼材の強度を予測する上で、どの元素を「全体的に」重視しているかを平均的な影響度の大きさで示しています。結果として、チタン (Ti)、コバルト (Co)、クロム (Cr)、アルミニウム (Al) などが特に重要な因子として学習されていることがわかります。

2. 元素は強度にどう影響するのか? (Beeswarm Plot)
Beeswarmプロットは、特徴量の値の大小と予測への影響の方向・大きさを同時に示します。
- 炭素 ©: 赤い点(含有量が多い)は右側(正のSHAP値)に、青い点(少ない)は左側(負のSHAP値)に分かれ、「炭素量が多いほど強度は高くなる」という物理現象と一致した関係をモデルが学習しています。
- コバルト (Co): 赤い点は右側に多く、青い点は左側に多く分布し、含有量が多いほど強度を上げる傾向が示されています。
- クロム (Cr): 赤い点は左側(負のSHAP値)に集中し、含有量が多いほど強度を下げる傾向がモデルにより学習されています。

3. ある一つの鋼材の予測理由は? (Force Plotと定量的評価)
特定サンプルのForceプロットは、ベース値(全体の平均予測値)から各元素の貢献によって最終予測値に至る過程を示します。多くの元素が予測値を押し下げる方向に働いていることが視覚的にわかります。
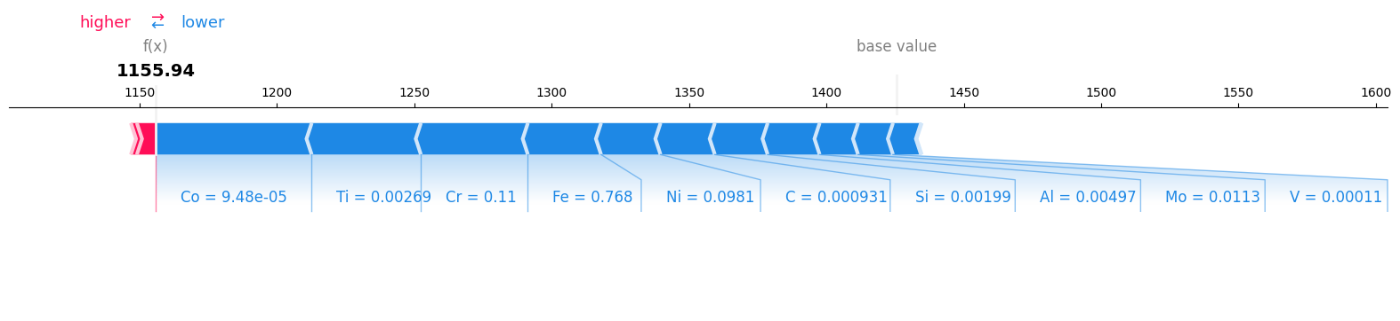
以下の表から、このサンプルの予測値1155.94はベース値1425.54からSHAP値の合計269.60を引いたものであり、SHAPが予測を完全に分解できていることがわかります。最大の影響因子はコバルト(Co)、次いでチタン(Ti)、クロム(Cr)であり、これらは予測値を下げる方向に働いています。一方、ニオブ(Nb)と窒素(N)はわずかに予測値を押し上げています。
| 元素 | 含有率 (Feature_Value) | SHAP値 (SHAP_Value) |
|---|---|---|
| Co | 0.000095 | -56.68 |
| Ti | 0.002690 | -39.76 |
| Cr | 0.110000 | -38.93 |
| Fe | 0.768000 | -26.64 |
| Ni | 0.098100 | -21.65 |
| C | 0.000931 | -19.77 |
| Si | 0.001990 | -19.24 |
| Al | 0.004970 | -18.91 |
| Mo | 0.011300 | -14.00 |
| V | 0.000110 | -12.69 |
| Mn | 0.002440 | -10.21 |
| Nb | 0.000060 | 6.96 |
| N | 0.000000 | 2.17 |
| W | 0.000000 | -0.24 |
コードの詳細解説
ソースコードの各ステップが、マテリアルズインフォマティクスのプロジェクトにおいてどのような意味を持つのか、より深く掘り下げて解説します。
ステップ0 & 1: 環境構築とライブラリのインポート
これは、料理で言えば調理器具と食材を揃える、プロジェクトの最も基本的な準備段階です。
# ===================================================================
# 0. 環境構築:必要なライブラリのインストール
# ===================================================================
!pip install matminer==0.9.3 pandas==2.2.2 scikit-learn==1.6.1
!pip install matplotlib==3.10.0 catboost==1.2.8 shap==0.48.0
# ===================================================================
# 1. 必要なライブラリのインポート
# ===================================================================
import pandas as pd
import matplotlib.pyplot as plt
import re
from matminer.datasets import load_dataset
from sklearn.model_selection import train_test_split
from catboost import CatBoostRegressor
import shap
from IPython.display import display, Image!pip install ...: Google Colaboratoryの環境に、今回の分析で必要な専門ライブラリをインストールするコマンドです。matminer: 材料科学に特化したライブラリで、ベンチマーク用のデータセットを数行のコードで簡単に呼び出すために使用します。catboost: 第2回でその性能を実証した、高性能な勾配ブースティングモデルを構築するためのライブラリです。shap: 今回の主役。学習済みモデルの予測根拠を説明するための、XAI(説明可能なAI)ライブラリです。
import ...: インストールしたライブラリを、Pythonコードの中で実際に使えるように宣言します。例えばimport pandas as pdと書くことで、これ以降pdという名前でpandasの機能(データフレームの操作など)を呼び出せるようになります。
ステップ2 & 3: データセットの読み込みと特徴量エンジニアリング
AIが学習できる「きれいな数値データ」を準備する、極めて重要な工程です。
# ===================================================================
# 2. データセットの読み込み & 3. 特徴量エンジニアリング
# ===================================================================
print("ステップ2&3: データセットの読み込みと特徴量エンジニアリング...")
df = load_dataset("matbench_steels")
def extract_value(composition_string, element_name): pattern = r"{}(\d+\.?\d*)".format(element_name) match = re.search(pattern, str(composition_string)) if match: return float(match.group(1)) else: return 0.0
elements = [ "Fe", "C", "Mn", "Si", "Cr", "Ni", "Mo", "V", "N", "Nb", "Co", "W", "Al", "Ti",
]
for element in elements: df[element] = df["composition"].apply(lambda x: extract_value(x, element))
df_clean = df.drop(columns=["composition"])
print("完了しました。")load_dataset("matbench_steels"):matminerの機能を使って、材料科学の論文で広く使われている鋼材のベンチマークデータを直接pandasのDataFrameとして読み込みます。このデータには、'composition'(化学組成式)と'yield strength'(降伏強度)の列が含まれています。extract_value関数とループ処理: AIモデルは**'Fe0.768C0.0009...'**のような文字列を直接理解できません。そこで、この文字列から各元素(Fe, Cなど)に対応する数値を一つずつ取り出す必要があります。- 正規表現:
reライブラリの正規表現r'{}(\d+\.?\d*)'は、「指定した元素名の直後に続く数値を抽出する」というルールを定義しています。 applyメソッド : このルール(自作関数)を、DataFrameの全データ行のcomposition列に適用し、結果を新しい列(‘Fe’, ‘C’, ‘Mn’など)として追加していきます。この一連の処理が「特徴量エンジニアリング」であり、生のデータからモデルが学習に使える特徴量(Feature)を生成する創造的なプロセスです。
- 正規表現:
ステップ4 & 5: 特徴量とターゲットの定義、データ分割
モデルに「何を」「何から」予測させるかを定義し、性能を公正に評価するための準備をします。
# ===================================================================
# 4. 特徴量とターゲットの定義
# ===================================================================
features = elements
target = "yield strength"
X = df_clean[features]
y = df_clean[target]
# ===================================================================
# 5. データを訓練用とテスト用に分割
# ===================================================================
print("\nステップ5: データを訓練データとテストデータに分割します...")
X_train, X_test, y_train, y_test = train_test_split( X, y, test_size=0.2, random_state=42
)
print("データの分割が完了しました。")- 特徴量
Xとターゲットy:Xには、予測の「原因」となるデータ、すなわち先ほど生成した元素含有率の列を全て格納します。yには、予測したい「結果」である降伏強度の列を格納します。
train_test_split: モデルの性能を公正に評価するための、機械学習における鉄則です。- 分割の目的: 手元にあるデータを「訓練データ(Train data)」と「テストデータ(Test data)」に分割します。モデルは訓練データ(教科書)だけを見て学習し、一度も見たことのないテストデータ(本番の試験)でその性能を評価されます。これにより、未知のデータに対する予測能力、すなわち「汎化性能」を正しく測ることができます。
test_size=0.2: 全データの20%をテスト用に確保することを意味します。random_state=42: データをランダムに分割する際の「乱数の種」を固定します。これを指定しないと、実行するたびに分割のされ方が変わり、結果が微妙に変動してしまいます。42(特に意味はない慣例的な数値)に固定することで、誰がいつ実行しても全く同じ結果が得られ、実験の再現性が担保されます。
ステップ6: CatBoostモデルの訓練
第2回で作成した高性能モデルを、準備したデータで学習させます。
# ===================================================================
# 6. CatBoostモデルの訓練
# ===================================================================
print("\nステップ6: CatBoost回帰モデルの学習を開始します...")
model = CatBoostRegressor(random_seed=42, verbose=0)
model.fit(X_train, y_train)
print("モデルの学習が完了しました。")model.fit(X_train, y_train): これが「学習」のコマンドです。CatBoostモデルに、訓練データの特徴量(X_train)とそれに対応する正解の降伏強度(y_train)を渡します。モデルは内部で、元素の含有率と強度の間の複雑で非線形な関係性を、多数の決定木を組み合わせて学習していきます。random_seed=42: モデルの内部でも乱数が使われる部分があるため、こちらも固定して結果の再現性を確保します。verbose=0: 学習の進捗状況に関する詳細なログ出力を抑制し、結果の表示を簡潔にするためのオプションです。
ステップ7: SHAPを用いたモデル解釈
学習が完了したモデルの「頭の中」を覗き見るための準備を行います。
# ===================================================================
# 7. SHAPを用いたモデル解釈
# ===================================================================
print("\nステップ7: SHAPを用いてモデルの解釈を行います...")
explainer = shap.TreeExplainer(model)
shap_values = explainer.shap_values(X_test)
print("SHAP値の計算が完了しました。")explainer = shap.TreeExplainer(model): SHAPの「説明器(Explainer)」を初期化します。SHAPにはいくつかの種類の説明器がありますが、CatBoostのような決定木ベースのモデルに対しては、その構造を利用して高速に計算できるTreeExplainerを使います。学習済みモデルmodelを渡すことで、説明器はモデルの内部構造(どのような決定木が、どのような順番で構築されたか)を解析する準備を整えます。shap_values = explainer.shap_values(X_test): 説明器に、解釈したいデータ(今回はテストデータX_test)を渡して、SHAP値を計算させます。この計算により、テストデータの 全てのサンプル に対し、全ての特徴量(元素)が、予測値を「平均的な予測値(ベース値)」からどれだけ動かしたかを示す貢献度が算出されます。
ステップ8: SHAPプロットによる可視化と定量的評価
算出したSHAP値はただの数値の集まりですが、SHAPライブラリはこれを多様なグラフで可視化し、直感的な理解を助けてくれます。
# ===================================================================
# 8. SHAPプロットによる可視化と定量的評価
# ===================================================================
print("\nステップ8: SHAPの可視化と定量的評価を行います...")
# (1) グローバルな特徴量重要度 (Summary Plot)
print("\n--- (1) グローバルな特徴量重要度 (Summary Plot) ---")
shap.summary_plot(shap_values, X_test, plot_type="bar")
# (2) 各特徴量の影響を詳細に可視化 (Beeswarm Plot)
print("\n--- (2) 各特徴量の影響の詳細 (Beeswarm Plot) ---")
shap.summary_plot(shap_values, X_test)
# (3) 個別の予測に対する貢献度を画像として保存 (Force Plot)
print("\n--- (3) 個別の予測に対する貢献度 (Force Plot) ---")
force_plot = shap.force_plot( explainer.expected_value, shap_values[0, :], X_test.iloc[0, :], matplotlib=True, show=False,
)
plt.savefig("shap_force_plot_sample.png", format="png", bbox_inches="tight")
plt.close()
print("Forceプロットを 'shap_force_plot_sample.png' として保存しました。")
display(Image("shap_force_plot_sample.png"))
# (4) 個別の予測貢献度を数値で確認
print("\n--- (4) 個別の予測貢献度を数値(SHAP値)で確認 ---")
shap_df = pd.DataFrame({"Feature_Value": X_test.iloc[0], "SHAP_Value": shap_values[0]})
shap_df["SHAP_abs"] = shap_df["SHAP_Value"].abs()
shap_df_sorted = shap_df.sort_values(by="SHAP_abs", ascending=False).drop( columns=["SHAP_abs"]
)
base_value = explainer.expected_value
predicted_value = model.predict(X_test.iloc[[0]])[0]
shap_sum = shap_df["SHAP_Value"].sum()
print(f"ベース値 (平均予測値): {base_value:.2f}")
print(f"このサンプルの予測値: {predicted_value:.2f}")
print(f"SHAP値の合計: {shap_sum:.2f}")
print(f"予測値 - ベース値: {(predicted_value - base_value):.2f}")
print("\n貢献度が大きい順に並べた特徴量とSHAP値:")
display(shap_df_sorted)
print("\n処理はすべて完了しました。")- (1) グローバルな特徴量重要度 (Summary Plot – bar): 全サンプルのSHAP値の「絶対値の平均」を特徴量ごとに計算し、棒グラフで表示します。これは「モデルが全体として、どの元素を予測の重要な手がかりとしているか」を大局的に把握するためのものです。絶対値を取るため、予測を上げるか下げるかの方向性は考慮されず、純粋な影響の「大きさ」のみが評価されます。
- (2) 各特徴量の影響の詳細 (Beeswarm Plot): より情報量の多い、SHAPの代表的なプロットです。各点が「あるサンプルにおける、ある特徴量のSHAP値」を表します。横軸がSHAP値(貢献度)、点の色がその特徴量の値の大小(赤が高い、青が低い)を示します。これにより、「ある元素の含有量が高い(赤い点)と、予測値は上がる傾向にあるのか(右側)、下がる傾向にあるのか(左側)」といった、より詳細で深い関係性を一目で読み取ることができます。
- (3) 個別の予測に対する貢献度 (Force Plot): 特定の1サンプル(今回はテストデータの0番目)の予測を分解して可視化します。モデルの予測値が、ベースライン(全データの平均予測値)から、各元素の貢献によってどのように押し上げられたり(赤い矢印)、押し下げられたり(青い矢印)して最終的な値になったかを示します。
matplotlib=Trueを指定することで、論文やレポートに使いやすい静的な画像としてプロットを生成できます。 - (4) 個別の予測貢献度を数値で確認: Forceプロットの視覚的な理解を、定量的な数値で裏付けます。
pandasのDataFrameを作成して、サンプルの「実際の含有率(Feature_Value)」と、その影響度である「SHAP値」を一覧表示します。これにより、「このサンプルの予測において、コバルトは具体的に-56.7MPaだけ強度を下げる方向に働いた」といった、極めて具体的な説明が可能になります。
最後に
3回にわたるハンズオンで、私たちはマテリアルズインフォマティクスの基本的な「型」をマスターしました。
- シンプルな線形回帰でベースラインを作り、その限界(過学習)を特定しました。
- 高性能なCatBoostを導入し、予測精度を飛躍させ、汎化性能を獲得しました。
- そして今回、SHAPを用いてそのモデルの思考プロセスを解明し、解釈性という魂を吹き込みました。
単に「当たる」だけのブラックボックスではなく、予測の根拠を対話的に説明できるAIは、もはや単なるツールではありません。材料科学者にとって、新たな発見を共に目指す「信頼できるパートナー」の誕生です。
しかし、このパートナーはまだ真のポテンシャルを発揮しきれていません。私たちが構築したCatBoostモデルは、いわば「デフォルト設定」のままです。モデルの性能を極限まで引き出すには、その内部設定であるハイパーパラメータを最適化する必要があります。
そこで次回は、この「最後のひと押し」でモデルをさらに磨き上げ、性能の頂点を目指します。
次回予告:マテリアルズインフォマティクス(MI)入門④【Optunaによるベイズ最適化で実践するハイパーパラメータチューニング】
Optunaという強力なフレームワークと、ベイズ最適化という効率的な探索手法を駆使し、無数の組み合わせの中から最高のハイパーパラメータを自動的に見つけ出します。今回手に入れた「解釈する力」を持つパートナーを、最強の予測モデルへと進化させる瞬間を、ぜひ次回の記事で体験してください。
Gaussianを使った量子化学計算の初心者向け技術書を販売中
しばしば出くわすエラーへの対処法をはじめ
Gaussianと無料ソフトウェア Avogadro を組み合わせた物性解析手法が学べます!

