
Google ChromeやSafariといったブラウザ上で、手持ちのデータからグラフを表示したり、データの解析を行ってみたいと思いませんか?
streamlitというpythonのライブラリを用いると、ブラウザ上で自動でデータ解析ができるWebアプリを簡単に作れるようになるんです。
今回は、データファイル(csv)を読み込み、その内容を自動で解析し、結果をブラウザに表示するところまでを扱います。
Webアプリでデータ解析ができるようになりますよ!
macOS Monterey(12.4), python3.7.10

Streamlitで作るデータ解析Webアプリの技術書を販売中
¥2,000 → ¥1,000 今なら50%OFF!!
データ解析をアプリで行う!
データ解析とグラフ描画を自動でしてくれるアプリが作れます!
データファイル(csv)を読み込んで、自動で解析してくれるアプリとは?
完成物
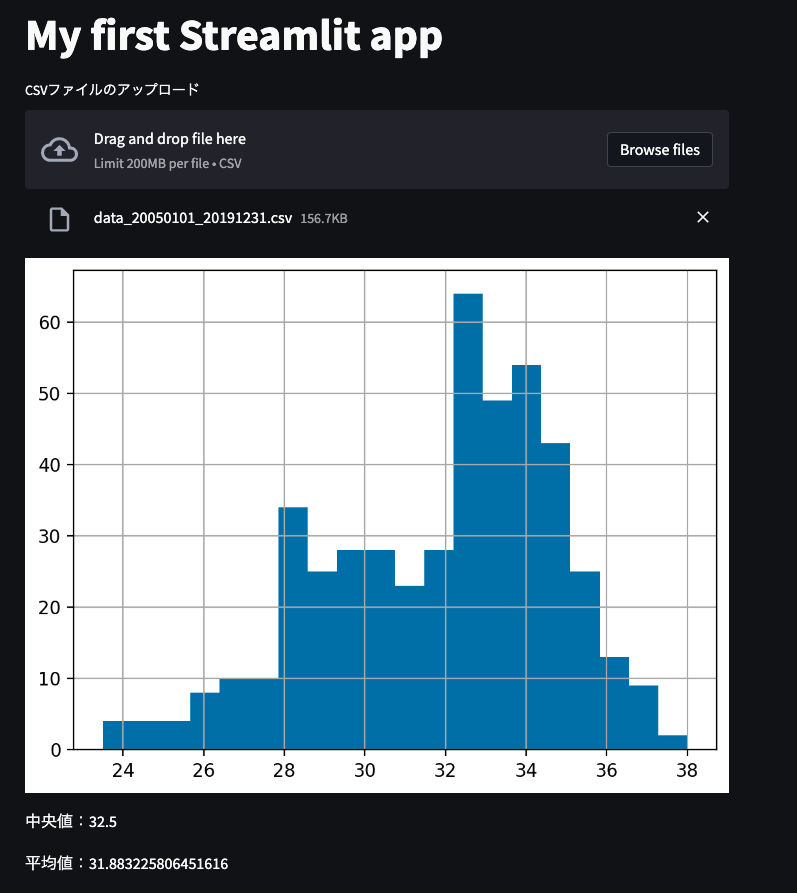
上のように、ドラッグ&ドロップでCSVファイルをアップロードし、自動で図を描画し、データ解析もしてくれるようなアプリを作ります。
上図は data_20050101_20191231.csv というCSVファイルをアップロードした結果、解析結果が表示された様子です。
このアプリが簡単に実装できちゃんです!
※ローカル環境なので、データが漏洩することはないです。
アプリの作成方法
ソースコード
以下のように、streamlitとpandasとnumpyなど複数のライブラリを使って実装します。
以下のコードをweb_input_and_calc.pyという名前で Desktop/labcode/python/web-data-analysis/Input_and_calc ディレクトリに保存します。
import streamlit as st
import pandas as pd
import numpy as np
import scipy as sp
import matplotlib.pyplot as plt
# ページのタイトル(なくてもいい)
st.title('My first Streamlit app')
# ファイルアップローダーの準備
uploaded_file = st.file_uploader("CSVファイルのアップロード", type="csv")
# uploadファイルが存在するときだけ、csvファイルの読み込みがされる。
if uploaded_file is not None:
# データファイルの読み込み
data_frame = pd.read_csv(uploaded_file, header=4, names=('date', 'max_degree', 'max_degree2', 'max_degree3', 'average_degree', 'average_degree2', 'average_degree3'), encoding="shift-jis")
# 7月と8月の情報だけ抽出
july_august_data = data_frame[data_frame['date'].astype(str).str.contains('/7/' or '/8/')]
# matplotlibで図を用意する
fig = plt.figure()
july_august_data['max_degree'].hist(bins=20)
# streamlit plot
st.pyplot(fig)
# 中央値の計算
median = sp.median(july_august_data['max_degree'])
# 平均値の計算
mean = np.mean(july_august_data['max_degree'])
st.write(f'中央値:{median}')
st.write(f'平均値:{mean}')プログラムを実行する
ターミナルを開き、
$ cd Desktop/labcode/python/web-data-analysis/Input_and_calcと入力し、ディレクトリを移動します。あとは以下のコマンドでstreamlitを起動させるだけです。( $マークは無視してください)
$ streamlit run web_input_and_calc.py少しすると自動的にブラウザで http://localhost:8501/ のページが開かれて、上でお見せしたページが表示されると思います。これだけです!
アップロードするCSVファイル
アップロードするCSVファイルはですが、本記事のアプリでは気象庁のページからダウンロードしてきたデータを用います。 以下にファイルの中身をお見せしていますが、大阪における、2005年1月1日から2020年12月31日までの 年月日、最高気温、平均気温の情報が格納されています。
data_20050101_20191231.csv という名前でファイルをご自身のPCの Desktop/labcode/python/web-data-analysis/Input_and_calc フォルダに保存してから、アップロードを試みてください。
ダウンロードした時刻:2022/09/06 06:40:57
,大阪,大阪,大阪,大阪,大阪,大阪
年月日,最高気温(℃),最高気温(℃),最高気温(℃),平均気温(℃),平均気温(℃),平均気温(℃)
,,,,,,
,,品質情報,均質番号,,品質情報,均質番号
2005/1/1,7.6,8,1,4.3,8,1
2005/1/2,9.0,8,1,4.7,8,1
2005/1/3,13.1,8,1,8.2,8,1
2005/1/4,13.5,8,1,8.6,8,1
2005/1/5,8.0,8,1,5.0,8,1
2005/1/6,7.3,8,1,5.3,8,1
2005/1/7,11.8,8,1,8.3,8,1
2005/1/8,8.7,8,1,5.2,8,1
2005/1/9,8.7,8,1,5.1,8,1
2005/1/10,8.2,8,1,4.1,8,1
2005/1/11,8.8,8,1,5.5,8,1
...
(2020年までつづく)各種ライブラリのインストール方法
ライブラリをインターネット上から自身のPCにダウンロードしていないと、 たとえ import streamlit as stと 記述しても使えません。 streamlitがないよ!という旨のエラーが出た場合は、pip installを使ってダウンロードしましょう。実行するディレクトリはどこでもOKです。
複数のライブラリを一度にまとめてインストールするには、以下のようにスペースを間にもうけて並べるとよいです。
$ pip install streamlit matplotlib numpy scipy pandasしばらくして、Successfullyという文言が出て来れば完了です。
コードの解説
上に書いたソースコードの解説をしていきます。
データの読み込みとグラフの描画に関しては、以前の記事で解説していますので、詳しくはそちらをご参照ください。
# データファイルの読み込み
data_frame = pd.read_csv(uploaded_file, header=4, names=('date', 'max_degree', 'max_degree2', 'max_degree3', 'average_degree', 'average_degree2', 'average_degree3'), encoding="shift-jis")
# 7月と8月の情報だけ抽出
july_august_data = data_frame[data_frame['date'].astype(str).str.contains('/7/' or '/8/')]読み込んだファイルの全データの中から今回は7月と8月だけに注目するために、july_august_dataという名前の変数に2005-2020年の間の7月と8月のデータ(31日 x 2ヶ月 x 16年 = 992点)だけを格納しています。
年月日のデータが yyyy/M/ddの形式をとっていることから、astype(str).str で文字列の型に変換した後に、contains('/7/' or '/8/') で7月と8月の情報を抜き取っています。
11月とか12月の情報を確認したい場合は、contains('/11/' or '/12/') とします。
例えば、2015年だけのデータだけ抜き取りたい場合は、contains('2015/') とします。
# matplotlibで図を用意する
fig = plt.figure()
july_august_data['max_degree'].hist(bins=20)
# streamlit plot
st.pyplot(fig)july_august_data['max_degree'].hist(bins=20) が重要な記述です。
july_august_data['max_degree'] :july_august_dataには年月日(date)や最高気温(max_degree)、平均気温(average_degree)のデータが含まれますが、その中からmax_degree だけを取り出しています。
.hist(bins=20) :
binsで指定した分解能でヒストグラムを作成してくれるpandasのメソッドです。 今回は20にしています。 数字を大きくすればするほどヒストグラムのバーの幅は狭くなり、解像度が上がりますが、バーごとのカウント数は小さくなります。
st.pyplot(fig)でグラフを描画しています。
# 中央値の計算
median = sp.median(july_august_data['max_degree'])
# 平均値の計算
mean = np.mean(july_august_data['max_degree'])
st.write(f'中央値:{median}')
st.write(f'平均値:{mean}')中央値と平均値をそれぞれscipyとnumpyのライブラリのメソッドを用いて計算しています。 自分で関数を作成して計算することもできますが、pythonには多くの計算用ライブラリが用意されているので、利用するといいでしょう。 あとはそれらの結果を st.write()で書き出しているだけです。
最後に
streamlitというpythonのライブラリを用いてWebアプリを簡単に作る方法をご紹介しました。
今回は、データファイル(csv)を読み込んで、自動で解析し、その結果の表示とグラフ描画を自動でおこなってくれるアプリを作成しました。
もっと複雑な解析をさせることももちろんできるので、 できることを増やして、自分専用のデータ解析アプリを作れるようにしていきましょう!
Streamlitで作るデータ解析Webアプリの技術書を販売中
¥2,000 → ¥1,000 今なら50%OFF!!
データ解析をアプリで行う!
データ解析とグラフ描画を自動でしてくれるアプリが作れます!

