
気温や湿度の鉛直方向の分布を測定した高層気象観測データが気象庁のウェブサイトで公開されています。ブラウザ上で日付や観測地点を選択することで,データが掲載されているウェブページにアクセスすることができます。ブラウザの上の操作はわかりやすい反面,毎日決まった時間に同じ作業を繰り返すような場合には,やや面倒に感じることがあります。
データが掲載されているページは,日付と観測地点さえわかればURLを指定することができます。今回は,ブラウザを開くことなくPythonでこのウェブページのファイルを取得し,解析して高層気象観測データを取得したいと思います。
ただし,ウェブスクレイピングと呼ばれるこの手法は,ウェブサイトによっては利用規約によって明確に禁止している場合もあります。また,禁止されていない場合であっても,大量のアクセスはサーバや通信帯域に多大な負荷をかけてしまうため,時間を置かない大量アクセス等は絶対にしないでください。常識的な範囲内で利用するようにしましょう。
macOS Monterey 12.6.2, Python 3.9.15, beautifulsoup4 4.11.2

Pythonでやってみる気象データ解析の技術書を販売中
¥2,500 → ¥1,500 今なら40%OFF!!
気象の勉強をされている方必読!
気象予報士でもある著者がわかりやすく解説
プログラムを公開しているのでお手元で試せます!
Pythonでウェブサイトにアクセス
ウェブサイトにアクセスするとは,インターネットに公開されているサーバ (Webサーバ) に対して,「ウェブページの内容が記述されたファイルを送信してください」と要求することです。
この要求は,普段はブラウザで行いますが,Pythonでは標準ライブラリのurllib.requestで行うことができます。要求するWebサーバとファイルはURLで指定します。
例に用いるウェブベージは,高層気象観測データが掲載されたページで,日付と時刻,観測地点を指定するとURLを特定することができます。
HTML解析ライブラリBeautifulSoup4
BeautifulSoup4はHTMLやXMLファイルの内容を解析してくれるPythonライブラリです。HTMLとは,ウェブページを作るのに用いられる形式です。ウェブページはHTMLという形式で書かれていますので,ウェブページの内容を取得するには,HTMLを解析する必要があります。実際に内容をご覧になりたい方は,ほとんどのブラウザで「開発者ツール」などと呼ばれている機能で見ることができますし,ブラウザでページを保存し,ファイルをエディタなどで開くと内容を見ることができます。
下のスクリーンショットはGoogle Chromeのデベロッパーツールで内容を見たときのものです。
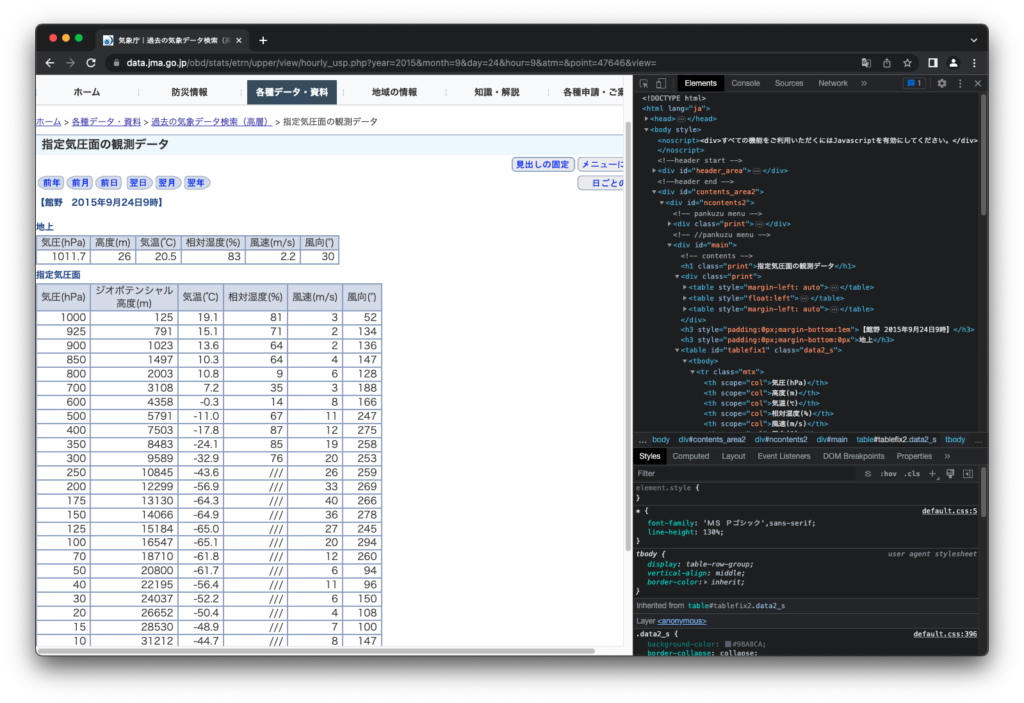
HTMLは<>で囲まれた「タグ」で文章構造が記述されています。また,タグに加えてclassやidといった情報が付与されることもあります。BeautifulSoup4はこれらをもとにファイルの内容を解析し,欲しいデータを取得することができます。
HTMLファイルのうち,ほしい部分 (高層気象観測データの表) に注目してみます。表は <table> タグで囲まれた部分で,2つあります (id=”tablefix1”とid=”tablefix2”)。id="tablefix1"のtableは次のような構造をしています。
<table id="tablefix1" class="data2_s">
<tbody>
<tr class="mtx">
<th scope="col">気圧(hPa)</th>
<th scope="col">高度(m)</th>
<th scope="col">気温(℃)</th>
<th scope="col">相対湿度(%)</th>
<th scope="col">風速(m/s)</th>
<th scope="col">風向(°)</th>
</tr>
<tr class="mtx" style="text-align:right;">
<td style="white-space:nowrap">1011.7</td>
<td class="data_0_0"> 26</td>
<td class="data_0_0">20.5</td>
<td class="data_0_0">83</td>
<td class="data_0_0">2.2</td>
<td class="data_0_0"> 30</td>
</tr>
</tbody>
</table>
<tr>タグで囲まれたひとまとまりが,ブラウザで閲覧したときの表の行(横ならび)をあらわしています。一行目はヘッダで,<th>タグで囲まれています。二行目以降はデータで,<td>タグで囲まれています。id="tablefix2"についても同様の構造です。
したがって,<tr>タグで囲まれた部分をひとまとまりとして,それが一行目かそれ以外かで,<th>または<td>タグで囲まれた部分を拾ってゆき,ファイルに書き出せばほしいデータファイルが得られることがわかります。
BeautifulSoupのインストール
BeautifulSoupはPython標準ライブラリではないので,自身の環境になければインストールする必要があります。pipで環境構築している方は,以下のコマンドでpip経由でインストールすることができます( $マークはプロンプトです。実際にはpip3から入力して,returnキーを押してください)。
$ pip3 install beautifulsoup4高層気象観測データの取得の実装
以上述べたことを基に,気象庁のウェブページから高層気象観測データを取得してみます。以下のコードをコピーして get-jmc-upper-air-soundings.py という名前で,適当なディレクトリ(ここでは,~/Desktop/labcode/python/plot-emagram とします)に保存します。
import urllib.request
from bs4 import BeautifulSoup
#---------------------------------------------------------
# 日付,観測時刻,観測地点番号
year = '2015'
month = '9' # ゼロ埋めしない
day = '24' # ゼロ埋めしない
hour = '9' # 観測時刻。'9' または '21' とする
point = '47646' # 館野
#---------------------------------------------------------
# 気象庁の高層気象観測データのページにアクセスする
url = f"<https://www.data.jma.go.jp/obd/stats/etrn/upper/view/hourly_usp.php?year={year}&month={month}&day={day}&hour={hour}&atm=&point={point}&view=>"
html_doc = urllib.request.urlopen(url).read()
# BeautifulSoupでHTMLを解析
soup = BeautifulSoup(html_doc, "html.parser")
#-------------------------------------------------------------
# id='tablefix1'の<table>を抽出
table01 = soup.find('table', id='tablefix1')
# 各行を解析する
header01 = []
rows01 = []
for i , tr in enumerate(table01.find_all('tr')):
# 一行目はヘッダ
if i == 0:
header = [th.text.strip() for th in tr.find_all('th')]
# 一行目以外はデータ
else:
rows01.append([td.text.strip() for td in tr.find_all('td')])
#-------------------------------------------------------------
# id='tablefix2'の<table>を抽出
table02 = soup.find('table', id='tablefix2')
# 各行を解析する
header02 = []
rows02 = []
for i , tr in enumerate(table02.find_all('tr')):
# 一行目はヘッダ
if i == 0:
header = [th.text.strip() for th in tr.find_all('th')]
# 一行目以外はデータ
else:
rows02.append([td.text.strip() for td in tr.find_all('td')])
#-------------------------------------------------------------
# データの書き出し
fout_path = f'{int(year):04d}{int(month):02d}{int(day):02d}_{int(hour):02d}JST_{point}.txt'
with open(fout_path, 'w') as fout:
# ヘッダ
fout.write(f'# {int(year):04d}{int(month):02d}{int(day):02d} {int(hour):02d}JST {point}\\n')
# tablefix1のデータ
for row in rows01:
fout.write('\\t'.join([td for td in row]) + '\\n')
# tablefix2のデータ
for row in rows02:
fout.write('\\t'.join([td for td in row]) + '\\n')
プログラムを実行する
ターミナルを開き,
$ cd ~/Desktop/labcode/python/plot-emagramと入力して,ディレクトリを移動します。あとは以下のコマンドを実行するだけです。( $マークは無視してください)
$ python3 get-jmc-upper-air-soundings.py実行結果
~/Desktop/labcode/python/plot-emagram に 20150924_09JST_47646.txt というファイルができて,以下のような内容になっていれば成功です!これは,前回の記事で使ったデータファイルと同じです!
# 20150924 09JST 47646
1011.7 26 20.5 83 2.2 30
1000 125 19.1 81 3 52
925 791 15.1 71 2 134
900 1023 13.6 64 2 136
850 1497 10.3 64 4 147
800 2003 10.8 9 6 128
700 3108 7.2 35 3 188
600 4358 -0.3 14 8 166
500 5791 -11.0 67 11 247
400 7503 -17.8 87 12 275
350 8483 -24.1 85 19 258
300 9589 -32.9 76 20 253
250 10845 -43.6 /// 26 259
200 12299 -56.9 /// 33 269
175 13130 -64.3 /// 40 266
150 14066 -64.9 /// 36 278
125 15184 -65.0 /// 27 245
100 16547 -65.1 /// 20 294
70 18710 -61.8 /// 12 260
50 20800 -61.7 /// 6 94
40 22195 -56.4 /// 11 96
30 24037 -52.2 /// 6 150
20 26652 -50.4 /// 4 108
15 28530 -48.9 /// 7 100
10 31212 -44.7 /// 8 147
5 /// /// /// /// ///
コードの解説
上に書いたソースコードの解説をしていきます。
import urllib.request
from bs4 import BeautifulSoupまず,必要なモジュールをインポートします。
#---------------------------------------------------------
# 日付,観測時刻,観測地点番号
year = '2015'
month = '9' # ゼロ埋めしない
day = '24' # ゼロ埋めしない
hour = '9' # 観測時刻。'9' または '21' とする
point = '47646' # 館野次に,日付,観測時刻,観測地点番号の設定をします。ここでは,2015年9月24日の日本時間9時の館野における観測データを指定しています。
#---------------------------------------------------------
# 気象庁の高層気象観測データのページにアクセスする
url = f"<https://www.data.jma.go.jp/obd/stats/etrn/upper/view/hourly_usp.php?year={year}&month={month}&day={day}&hour={hour}&atm=&point={point}&view=>"
html_doc = urllib.request.urlopen(url).read()
# BeautifulSoupでHTMLを解析
soup = BeautifulSoup(html_doc, "html.parser")気象庁の高層気象観測データのページにアクセスして,htmlファイルをhtml_docに格納します。これをBeautifulSoupにわたすと,BeautifulSoupオブジェクトができます。BeautifulSoupオブジェクトは,次で見るようにfindメソッドなどを提供してくれます。
#-------------------------------------------------------------
# id='tablefix1'の<table>を抽出
table01 = soup.find('table', id='tablefix1')
# 各行を解析する
header01 = []
rows01 = []
for i , tr in enumerate(table01.find_all('tr')):
# 一行目はヘッダ
if i == 0:
header = [th.text.strip() for th in tr.find_all('th')]
# 一行目以外はデータ
else:
rows01.append([td.text.strip() for td in tr.find_all('td')])
最初に,1つ目の表の部分を取り出します。soup.find('table', id='tablefix1') によって,’tablefix1'というidをもつ,<table>タグで囲まれた部分(のうち,1つ目のもの)を探索します。
上で述べたように,<table>タグで囲まれた部分は,その下に <tr>タグで囲まれた部分,<th>または<td>タグで囲まれた部分というように階層構造をなしています。<tr>タグで囲まれた部分は複数個あるので,.find_all() メソッドで引数で与えたタグで囲まれた部分を探索します。
探索されたものに対して,.text メソッドを使うと,そのタグで囲まれた部分のテキストを返してくれます。.strip() は余計なスペースを取り除くために追加しています。
#-------------------------------------------------------------
# id='tablefix2'の<table>を抽出
table02 = soup.find('table', id='tablefix2')
# 各行を解析する
header02 = []
rows02 = []
for i , tr in enumerate(table02.find_all('tr')):
# 一行目はヘッダ
if i == 0:
header = [th.text.strip() for th in tr.find_all('th')]
# 一行目以外はデータ
else:
rows02.append([td.text.strip() for td in tr.find_all('td')])2つ目の表に対しても同じ操作を行います。
#------------------------------------------------------------
# データの書き出し
fout_path = f'{int(year):04d}{int(month):02d}{int(day):02d}_{int(hour):02d}JST_{point}.txt'
with open(fout_path, 'w') as fout:
# ヘッダ
fout.write(f'# {int(year):04d}{int(month):02d}{int(day):02d} {int(hour):02d}JST {point}\\n')
# tablefix1のデータ
for row in rows01:
fout.write('\\t'.join([td for td in row]) + '\\n')
# tablefix2のデータ
for row in rows02:
fout.write('\\t'.join([td for td in row]) + '\\n')
最後にデータを書き出して終了です。'\\t'.join([td for td in row])は row というリストに格納された各データを,タブ区切りで出力するのに使われるテクニックです。
最後に
今回は,ウェブブラウザでデータを検索して,表をコピーして,エディタを開いてペーストして,適当な名前をつけて保存する,といった毎日やるには面倒な作業をpythonで行う手法 (ウェブスクレイピング (もどき) ) を紹介しました。うまく使えば業務効率の改善に繋がります。
しかし,何度も言いますが,この手法は,ウェブサイトによっては利用規約によって明確に禁止している場合もあります。また,禁止されていない場合であっても,大量のアクセスはサーバや通信帯域に多大な負荷をかけてしまうため,時間を置かない大量アクセス等は絶対にしないでください。常識的な範囲内で利用するようにしましょう。
参考ウェブサイト
- Beautiful Soupのページ:https://www.crummy.com/software/BeautifulSoup/bs4/doc/
- 表のスクレイピング:https://scrapfly.io/blog/how-to-scrape-tables-with-beautifulsoup/
- リストに格納された要素をタブ区切りで出力:https://chaingng.github.io/post/python_list_tab/
Pythonでやってみる気象データ解析の技術書を販売中
¥2,500 → ¥1,500 今なら40%OFF!!
気象の勉強をされている方必読!
気象予報士でもある著者がわかりやすく解説
プログラムを公開しているのでお手元で試せます!
![[RF Diffusion] Discovery of Protein Drugs using RF Diffusion, ProteinMPNN, and AF2 [In silico Drug Discovery]](https://labo-code.com/wp-content/uploads/2023/04/Python関連-160x160.png)
